Title page

会议:暂无
年份:2022
github链接:https://github.com/IDEACVR/DINO
pdf链接:https://arxiv.org/abs/2203.03605
Summary
- DINO (DETR with Improved deNoising anchOr box) improves over previous DETR-like models in performance and efficiency based on DN-DETR(add ground truth labels and boxes with noises into the Transformer decoder layers), DAB-DETR(formulate queries in decoder as dynamic anchor boxes and refine them step-by-step across decoder layers), and Deformable DETR(deformable attention) by using
- to improve the one-to-one matching, we propose a contrastive denoising training by adding both positive and negative samples of the same ground truth at the same time → Avoid duplicate outputs of the same target
- a mixed query selection method for anchor initialization by selecting initial anchor boxes as positional queries from the output of the encoder while leaving the content queries learnable as before, encouraging the first decoder layer to focus on the spatial prior.
- a look forward twice scheme for box prediction
Workflow
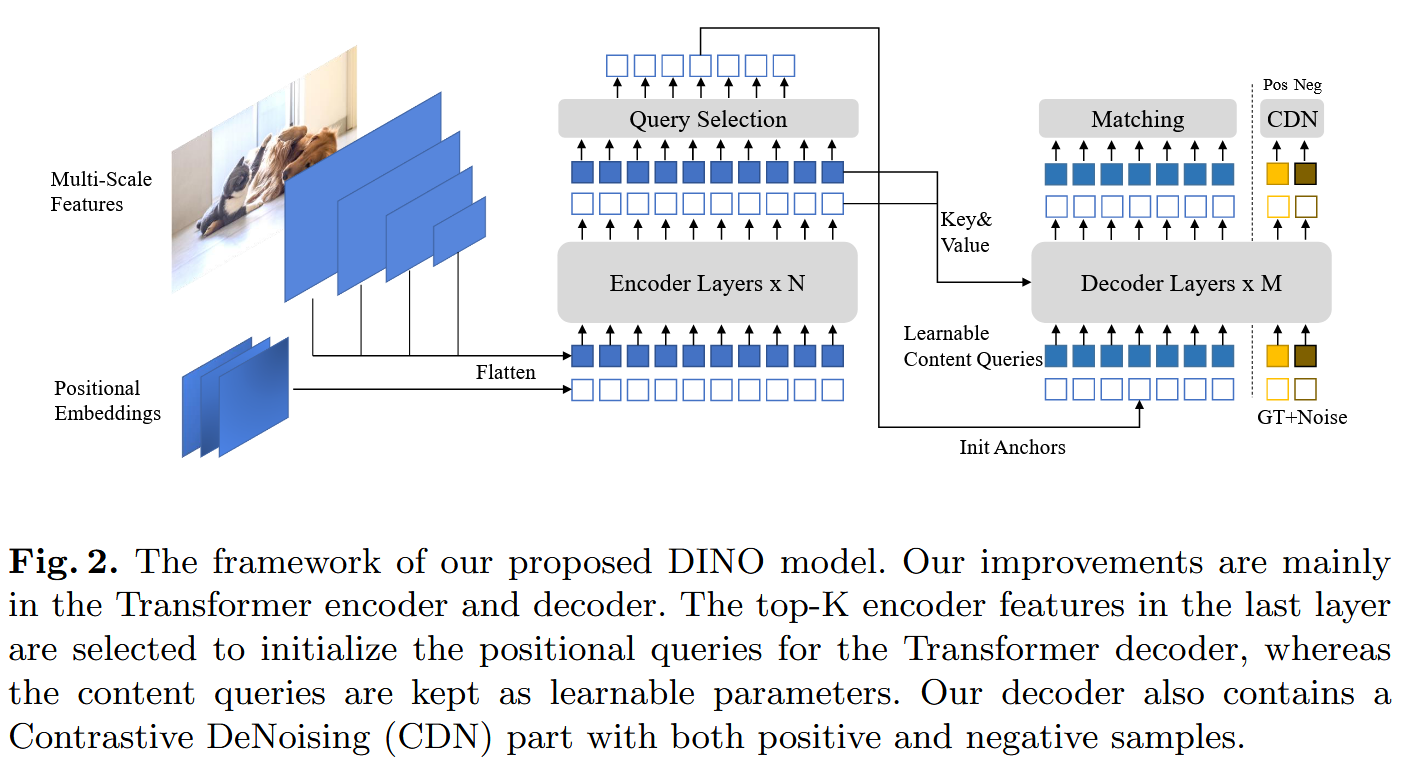
- 输入图像后,从backbone中提取多尺度特征(ResNet/Swin Transformer)
- 将多尺度特征和其对应的位置编码送入编码器
- 编码器的输出进行query selection,来初始化decoder中作为positional queries的anchors,content queries不进行初始化并保持可学习状态
- encoder中的跨注意力使用了可变注意力
- 使用对比去噪训练方法
- a novel look forward twice method is proposed to pass gradients between adjacent layers
辅助理解图
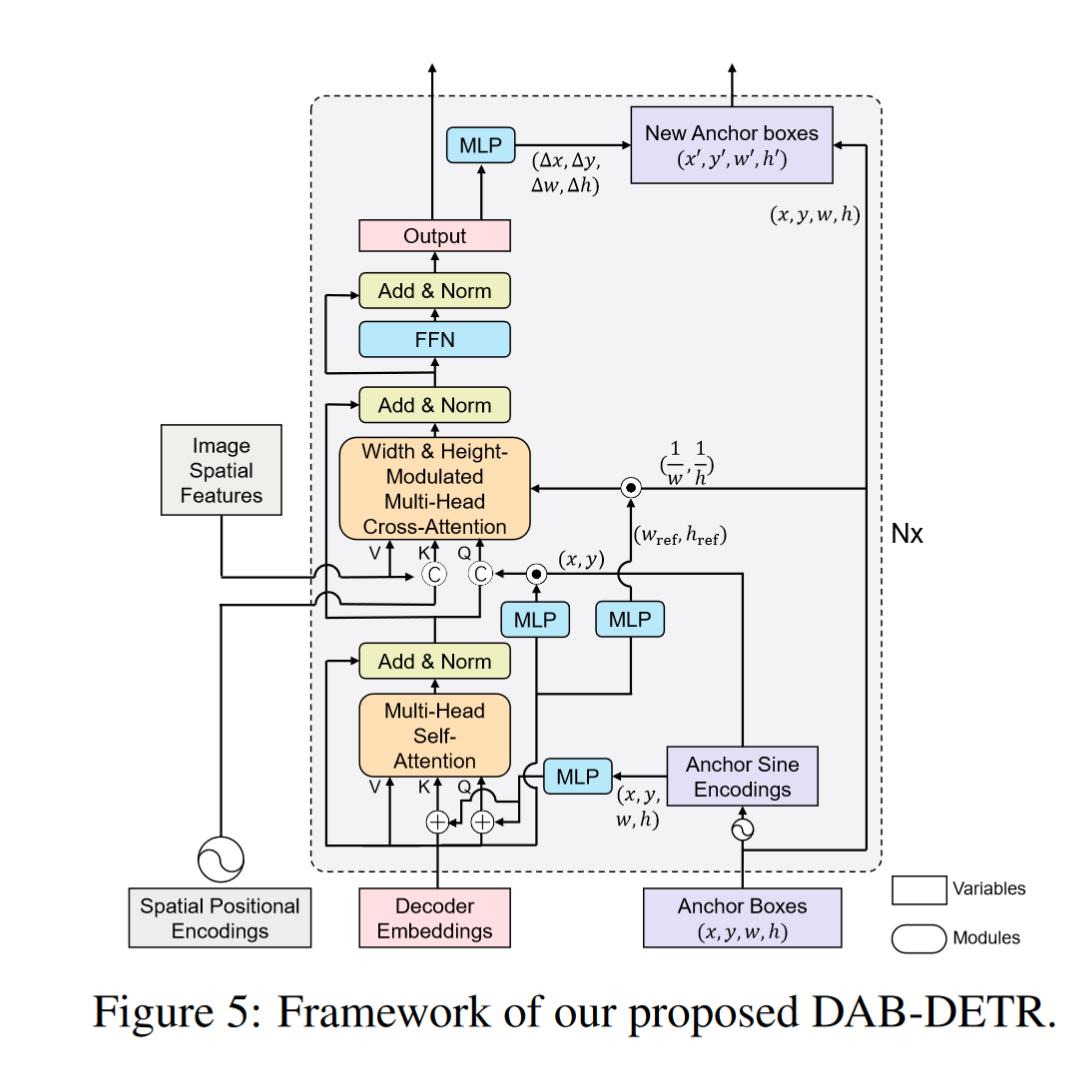
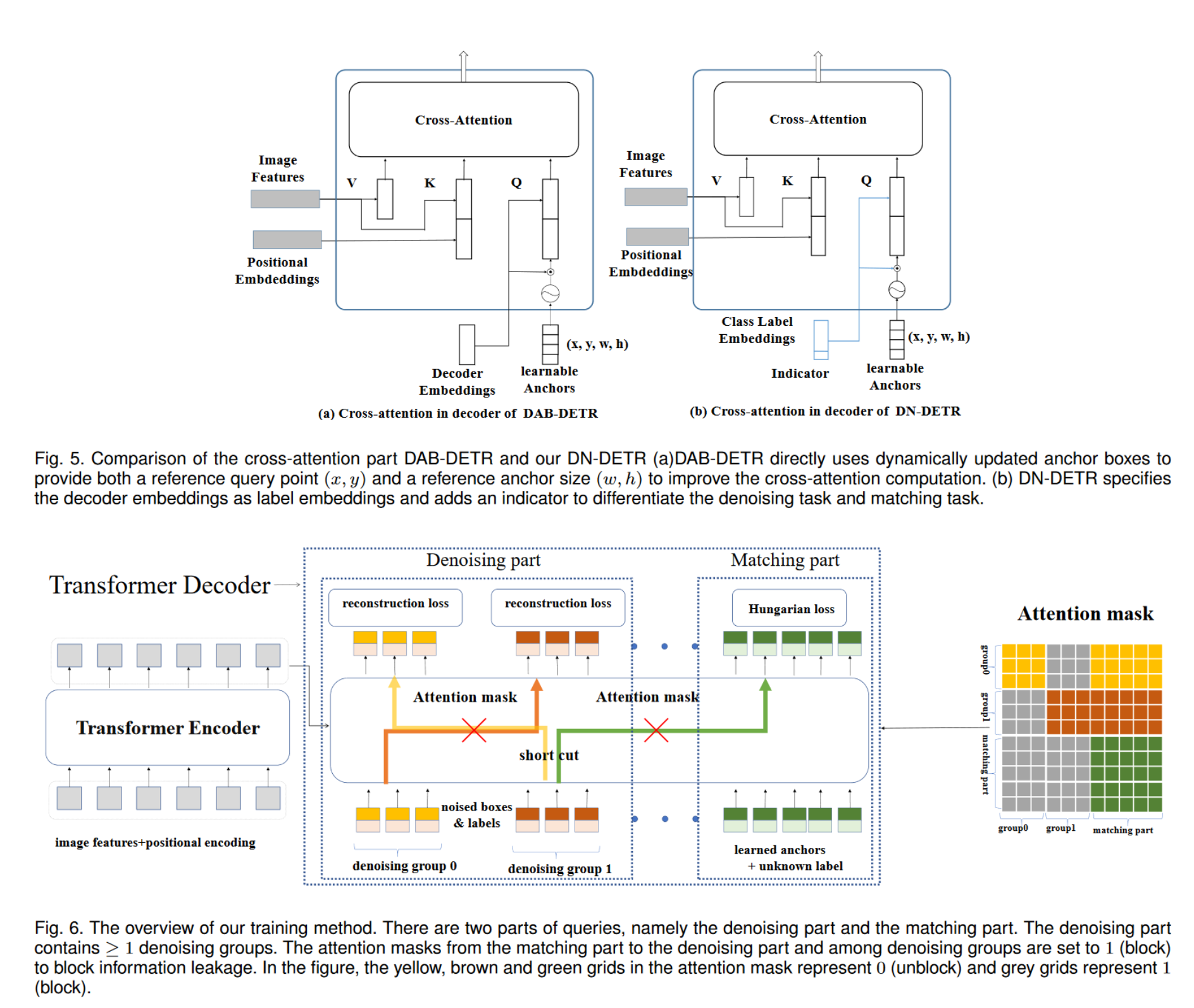
Methods
Contrastive DeNoising Training
作者认为 DN-DETR的方法可以学习去预测GT boxes附近的anchors,但是缺少预测”no object” 这类 anchors的能力,因此提出了对比去噪(contrastive denosing, CDN)的方法来拒绝那些没用的anchors
实现方法:

- In our method, we have two hyper-parameters λ1 and λ2, where λ1 < λ2.
- we generate two types of CDN queries: positive queries and negative queries.
- Positive queries within the inner square have a noise scale smaller than λ1 and are expected to reconstruct their corresponding ground truth boxes.
- Negative queries between the inner and outer squares have a noise scale larger than λ1 and smaller than λ2. They are are expected to predict “no object”
- Each CDN group has a set of positive queries and negative queries. If an image has n GT boxes, a CDN group will have 2 × n queries with each GT box generating a positive and a negative queries.
- 损失函数:The reconstruction losses are l1 and GIOU losses for box regression and focal loss for classification. The loss to classify negative samples as background is also focal loss.
有效性分析:
-
减少了重复预测
-
减少了阴性anchors的错误预测
Mixed Query Selection
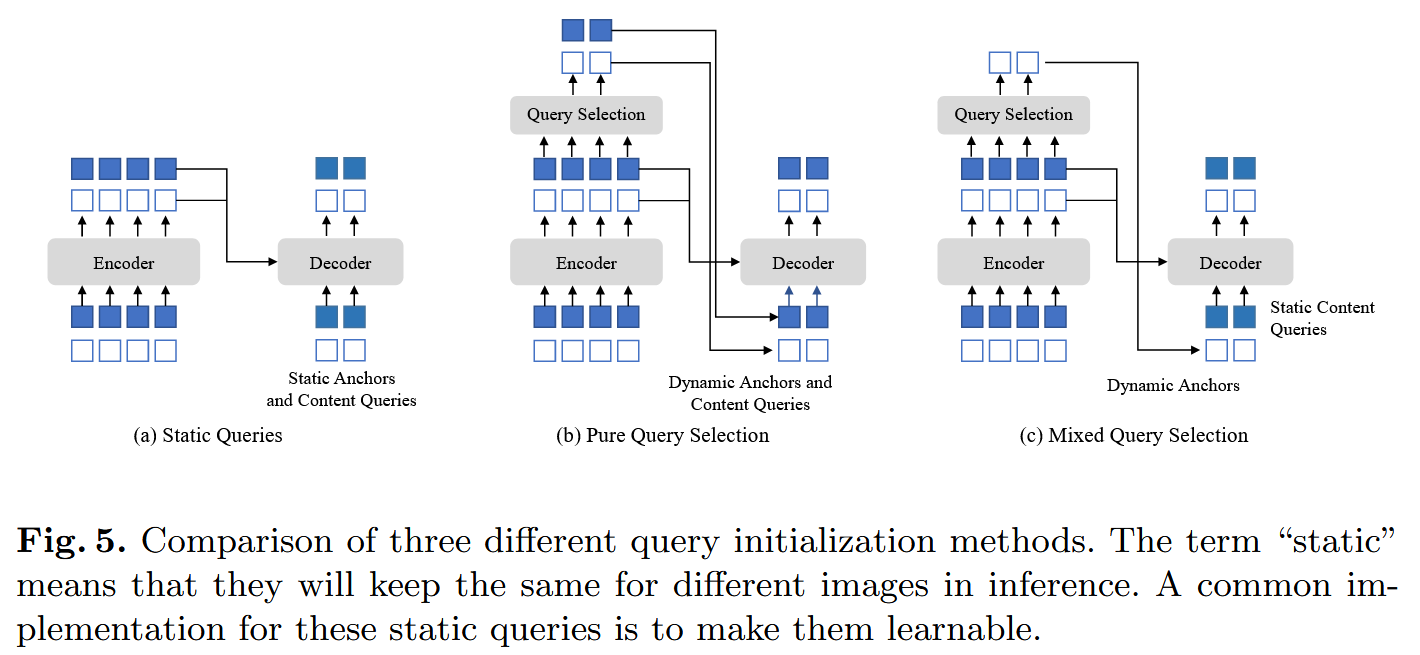
(a) decoder的queries与encoder features没有关系,初始化是static embeddings
(b) both the positional and content queries are generated by a linear transform of the selected features. In addition, these selected features are fed to an auxiliary detection head to get predicted boxes, which are used to initialize reference boxes.
(c) only initialize anchor boxes using the position information associated with the selected top-K features, but leave the content queries static as before. 作者认为 (b)的方法可能会误导decoder
Look Forward Twice
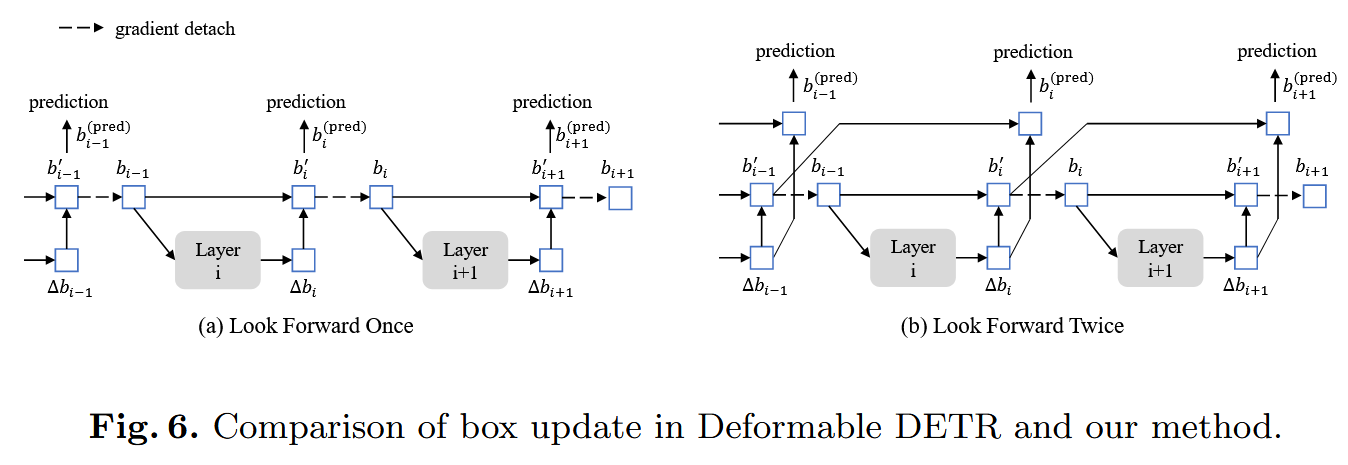
we conjecture that the improved box information from a later layer could be more helpful to correct the box prediction in its adjacent early layer.

Result-show
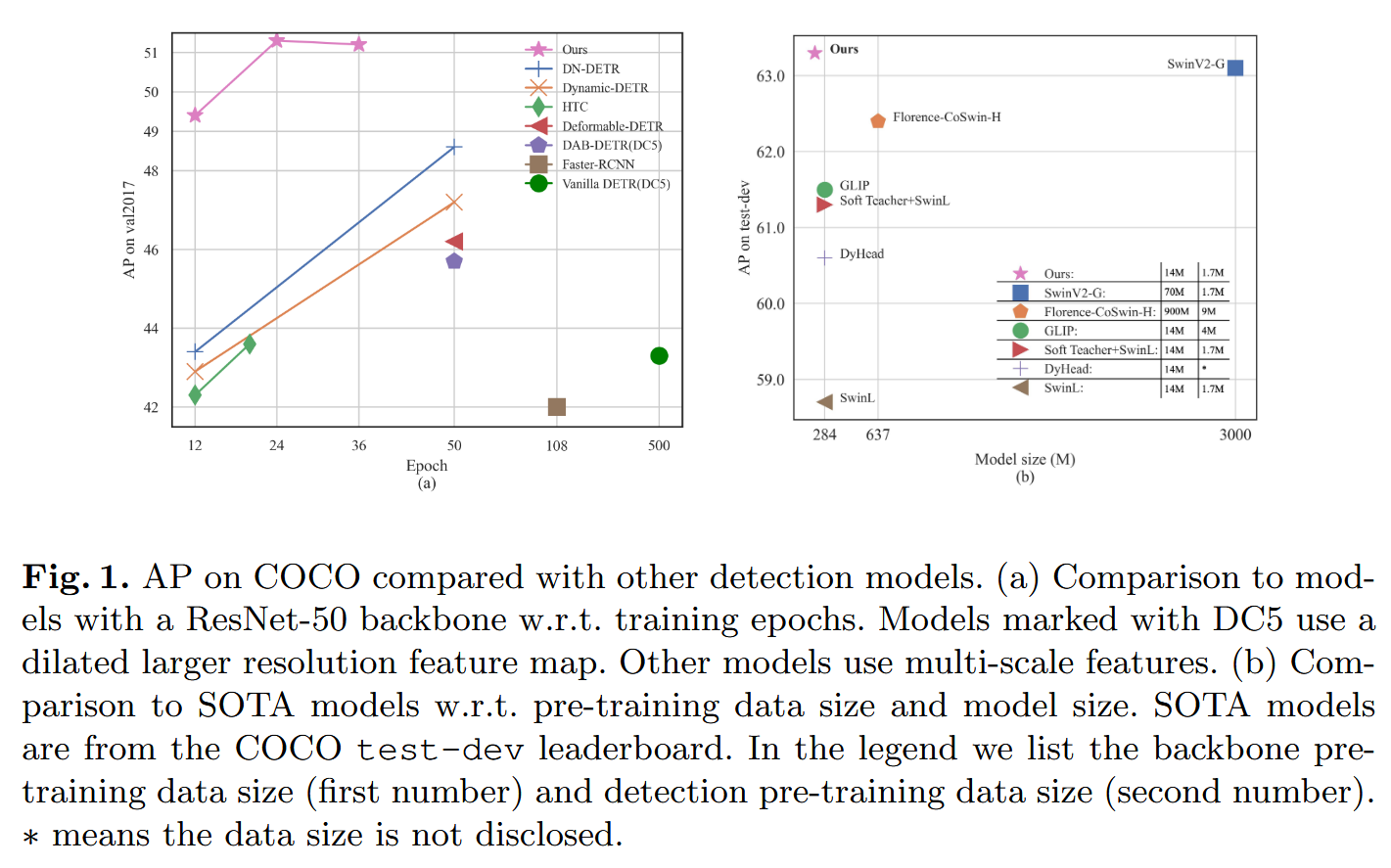
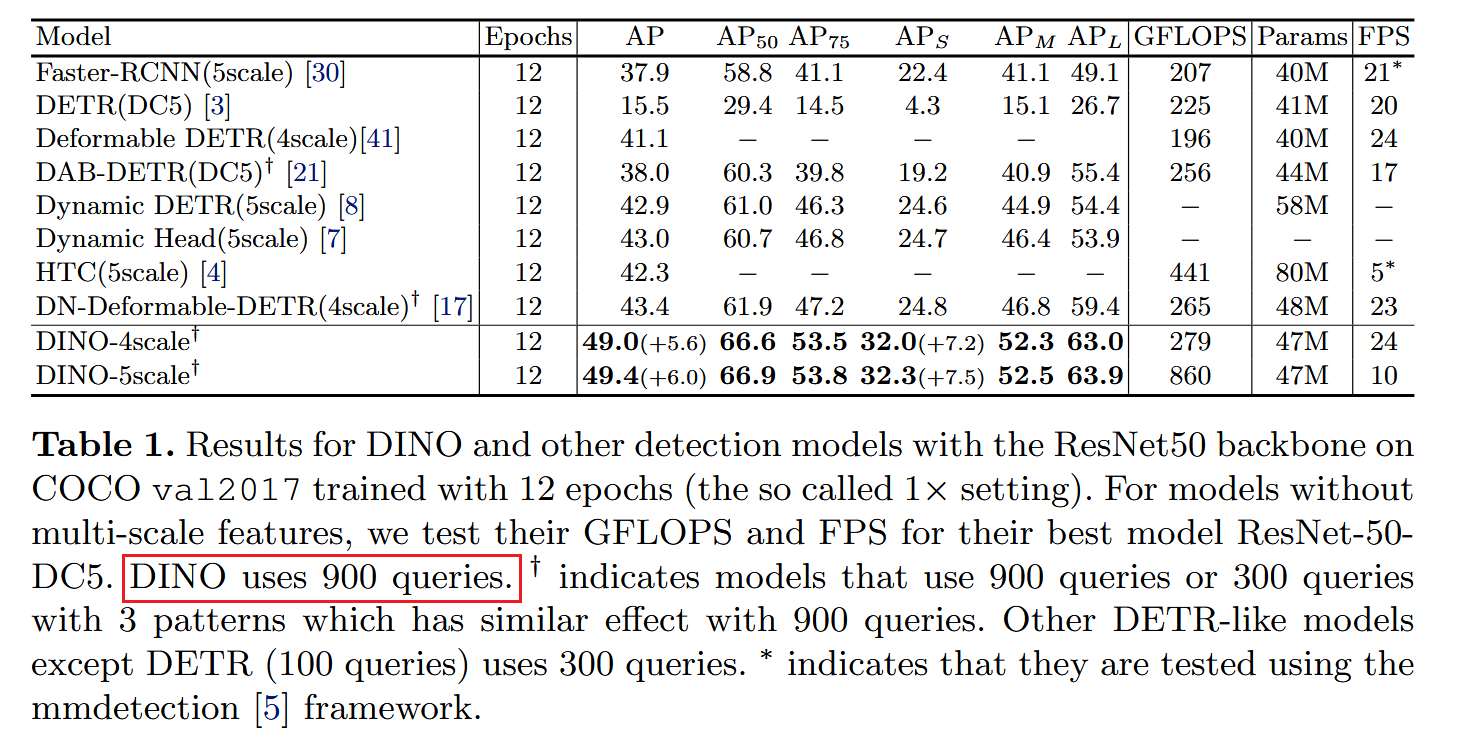
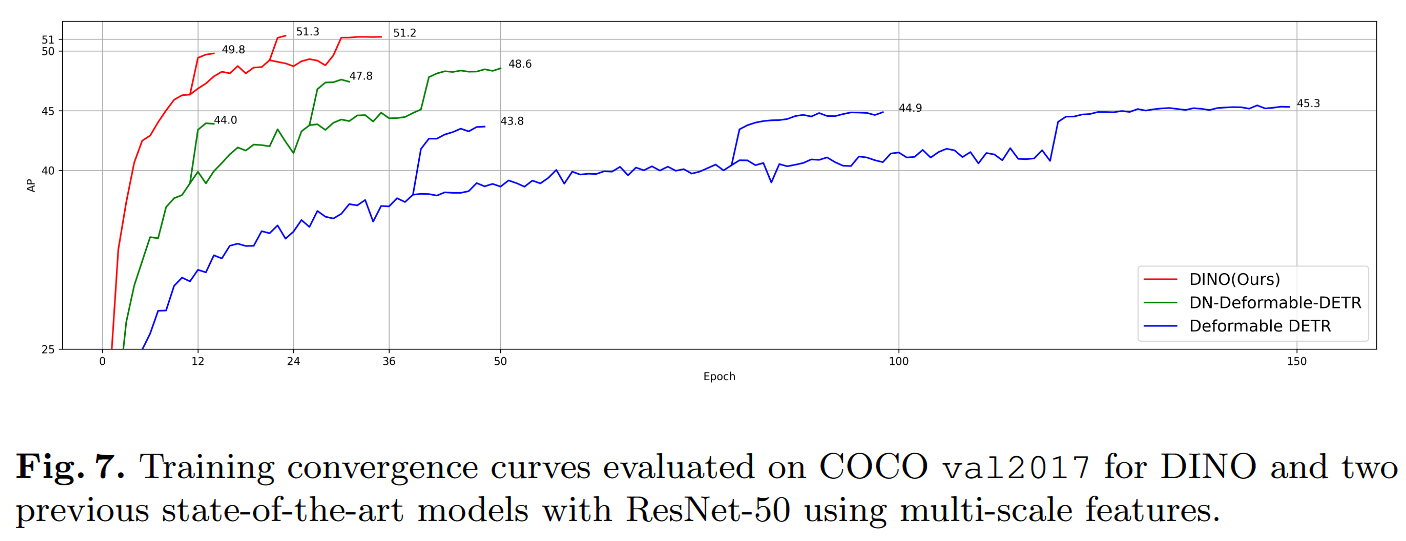
启发和思考
代码注释
1