Title page

会议:Accepted at CVPR
年份:2022
github链接:https://github.com/IDEA-Research/DN-DETR
pdf链接:https://arxiv.org/pdf/2010.04159.pdf
Summary
- We present in this paper a novel denoising training method to speed up DETR (DEtection TRansformer) training and offer a deepened understanding of the slow convergence issue of DETR-like methods (离散的、不稳定的二分图匹配 → 早期训练阶段时优化目标不一致).
- 收敛慢的问题,既往研究通过修改模型结构/将DETR的query与特定的空间位置相联系(如Conditional DETR/ DAB-DETR, Deformable DETR/ Anchor DETR),但少有研究关注于二分图匹配需要更有效的训练方式
- 为此,作者额外给GT boxes增加噪声后喂给decoder,并且训练模型来重建原始boxes → 减少了二分图匹配的困难度,增加了收敛速度
- Feed noised GT bounding boxes as noised queries together with learnable anchor queries into Transformer decoders
- Both kinds of queries have the same input format of (x, y, w, h)
- For noised queries, we perform a denoising task to reconstruct their corresponding GT boxes, 并且noised queries没有必要进行二分图匹配 → an easier auxiliary task
- For other learnable anchor queries, we use the same training loss and bipartite matching as in the vanilla DETR
- we also regard each decoder query as a bounding box + a class label embedding so that we are able to conduct(引导) both box denoising and label denoising.
- Our loss function consists of two components. One is a reconstruction loss and the other is a Hungarian loss
- 作者认为该方法通用+可在detr-like模型中即插即用
- we utilize DAB-DETR to evaluate our method since their decoder queries are explicitly formulated as 4D anchor boxes (x, y, w, h)
- For DETR variants that only support 2D anchor points such as anchor DETR, we can do denoising on anchor points.
- For those that do not support anchors like the vanilla DETR, we can do linear transformation to map 4D anchor boxes to the same latent space as for other learnable queries.
Workflow
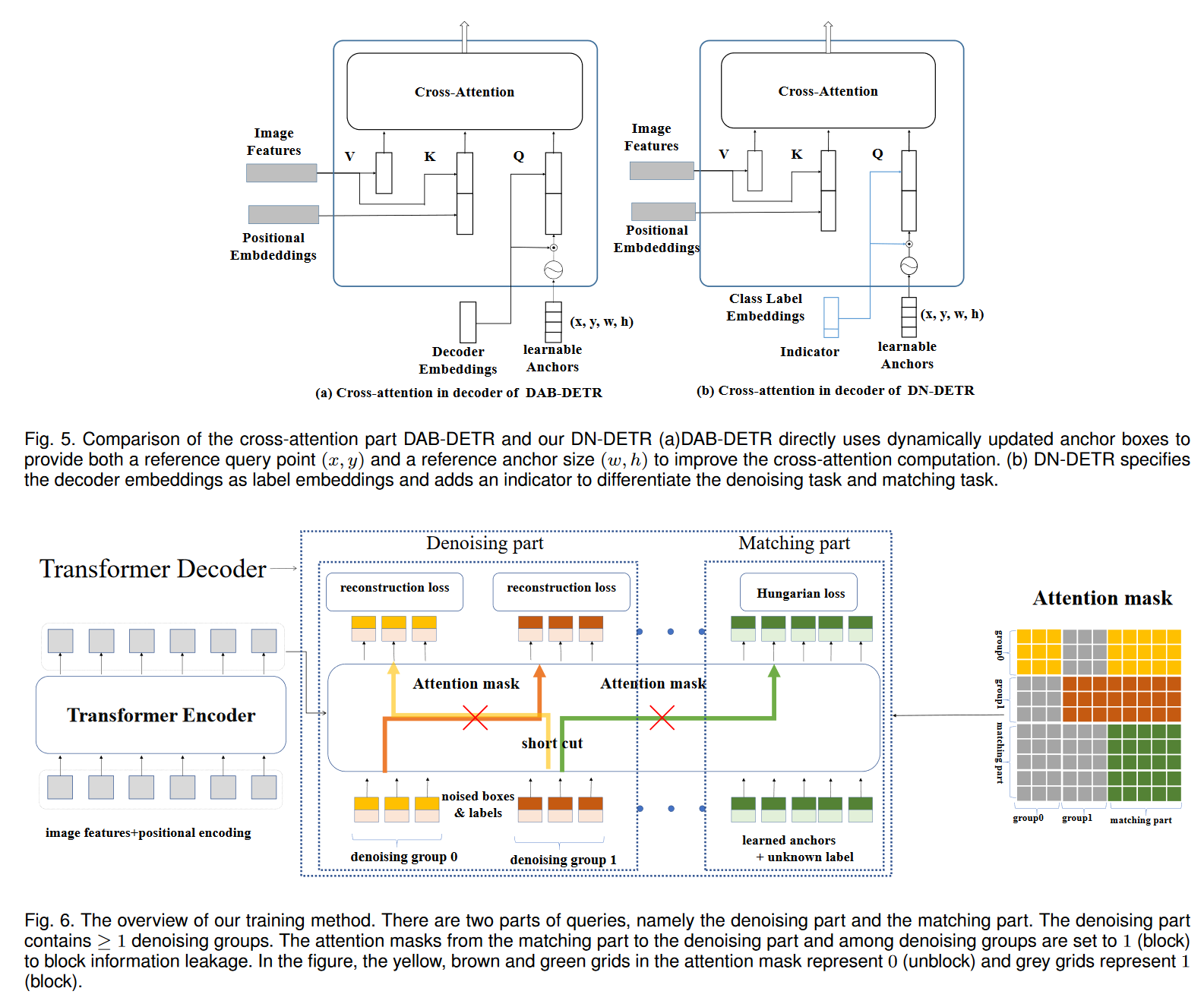
基本模型结构为DAB-DETR。decoder的positional queries都是显式地使用box坐标(x, y, w, h)来表示,但decoder embedding这边使用了 class label embedding+Indicator的方式。
-
Decoder queries as \(\bold{q} = {q_0, q1_, ..., q_{N−1}}\) , the output of the Transformer decoder as \(\bold{o} = {o_0, o_1, ..., o_{N−1}}\). F and A to denote the refined image features after the Transformer encoder, and the attention mask derived based on the denoising task design. \(\bold{o} = D(\bold{q}, F|A)\) where D denotes the Transformer decoder.
-
Decoder queries (\(\bold{q}\)) 分为两个部分
-
matching part
- 输入:learnable anchors(和DETR中相同的处理方法)
- 输出处理同DETR,the matching part adopts bipartite graph matching and learns to approximate the ground-truth box-label pairs with matched decoder outputs.
-
denoising part
- 输入:加入噪声的ground-truth (GT) box-label pairs(又叫 GT objects)
- 输出用于重建GT objects
-
Abuse the notations
-
\(\bold{q} = {q_0, q_1, ..., q_{K−1}}\) as denoising part
-
\(\bold{Q} = {Q_0, Q_1, ..., Q_{L−1}}\) as matching part
-
-
- 多个group:使用了不同的noised GT objects,来提高去噪效率
- Attention map (A):避免信息从denoising part泄漏到matching part
Methods
Stablize Hungarian Mathcing
文章设计了一个指标来量化二分匹配结果的不稳定性

Denoising
-
对每一张图像,都对GT objects添加了随机噪声(both bounding boxes and class labels),并使用了multiple noised versions
-
对于图像
-
center shifting 中心点漂移,保证中心点仍然在真实框内部并进行漂移。

-
box scaling 框缩放,可以随机缩放框的长和宽。
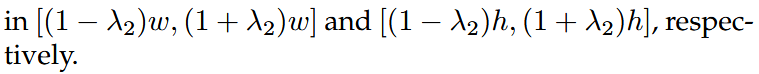
-
-
对于标签:使用了label flipping, 随机将一些GT labels翻转为其他label,使用超参数\(\gamma\)来控制flip labels的比例
-
损失函数:
- boxes: l1 loss 和 GIOU loss
- class labels: focal loss
-
该部分只在训练时有用
Attention Mask
使用目的:确保 ① matching part不能见到denoising part ② denoising groups之间不能相互见到

实现方式:

Label Embedding
除了COCO 2017的80个classes,还在matching part中增加了一个unknown class embedding,用来和denoising part保持语义一致性
此外,还增加了一个indicator:1表示属于denoising part,0表示属于matching part
Result-show
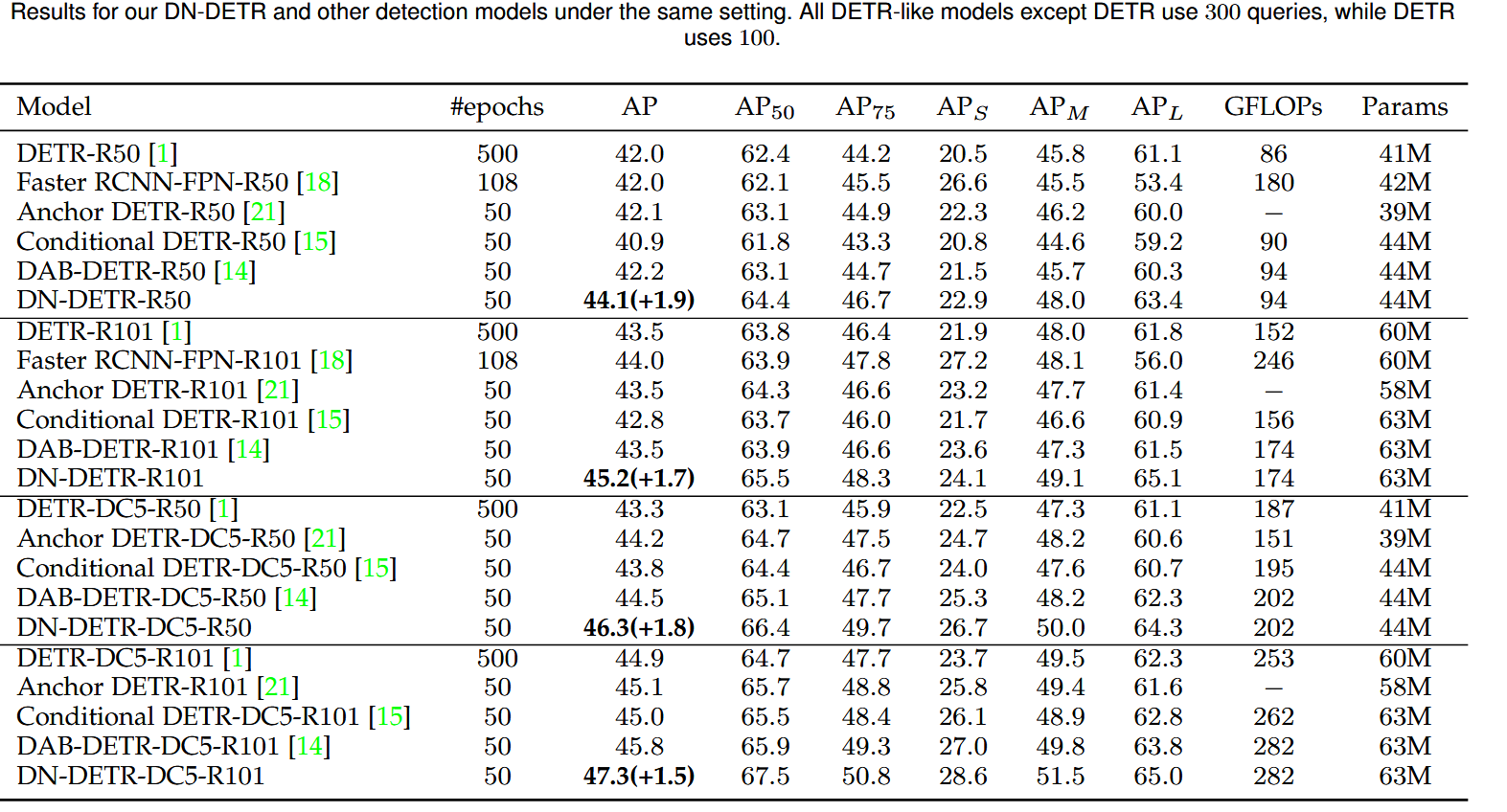
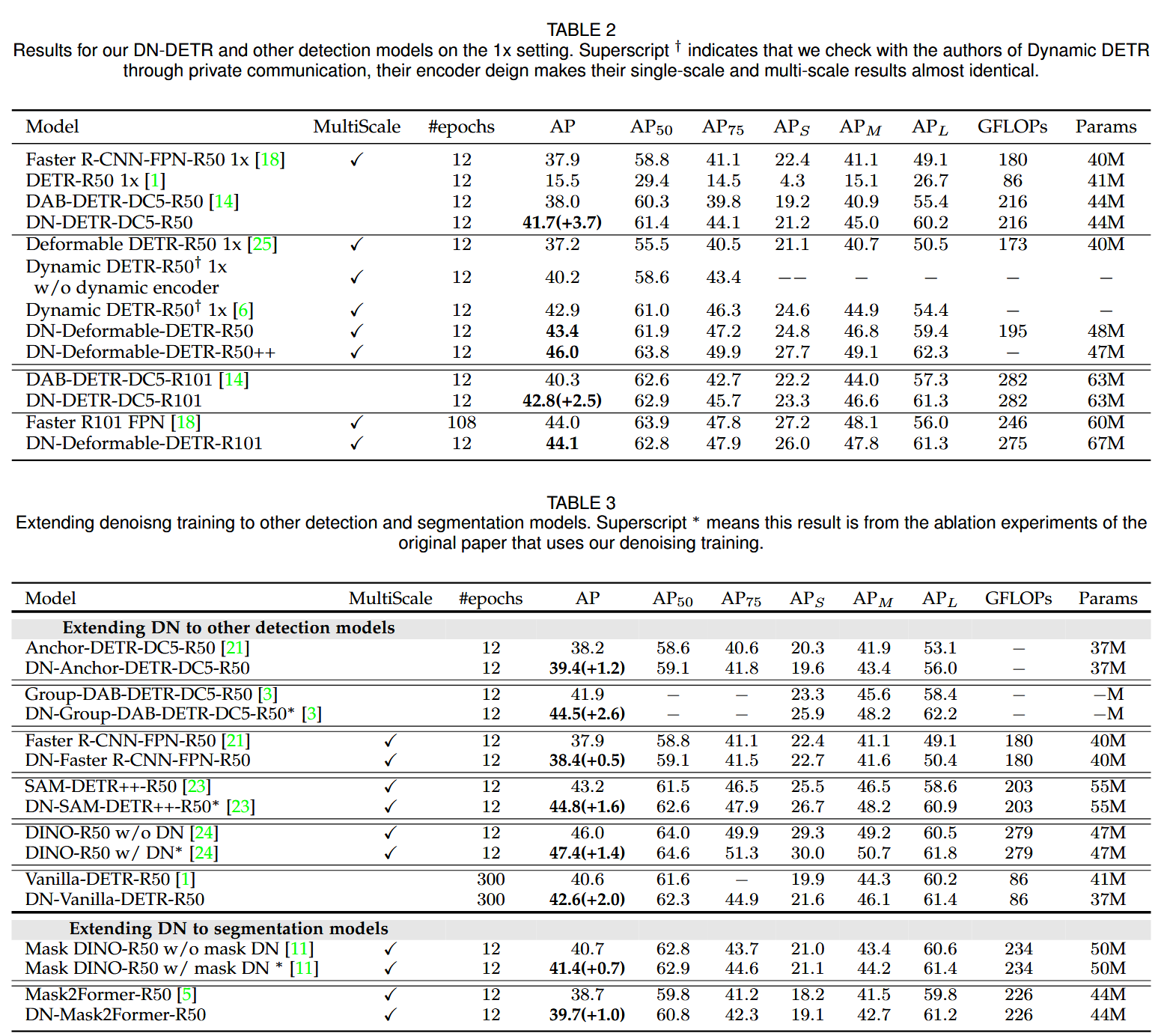
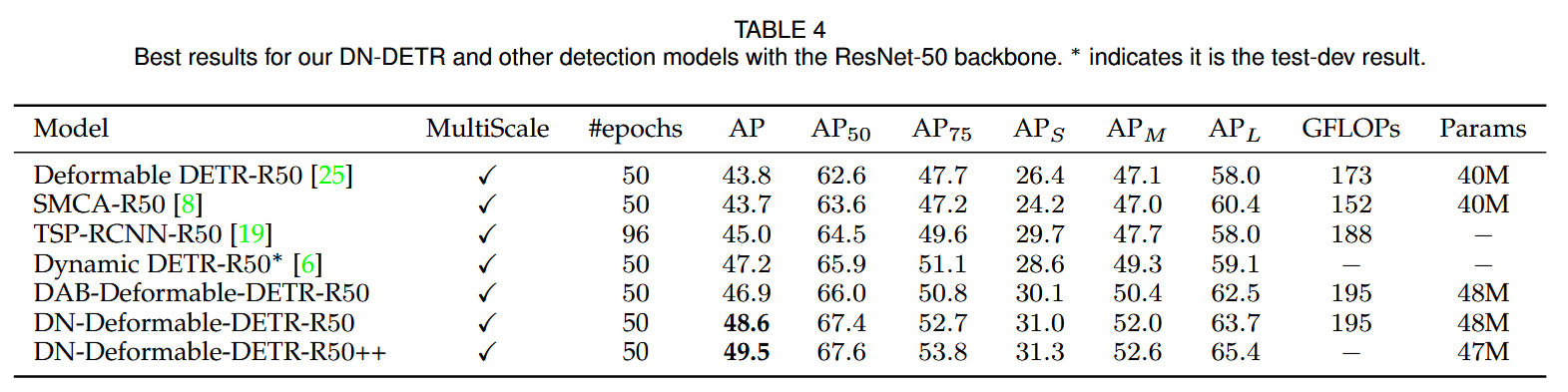
启发和思考
代码注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
def prepare_for_dn(dn_args, embedweight, batch_size, training, num_queries, num_classes, hidden_dim, label_enc):
"""
prepare for dn components in forward function
Args:
dn_args: (targets, args.scalar, args.label_noise_scale,
args.box_noise_scale, args.num_patterns) from engine input
embedweight: positional queries as anchor
training: whether it is training or inference
num_queries: number of queries
num_classes: number of classes
hidden_dim: transformer hidden dimenstion
label_enc: label encoding embedding
Returns: input_query_label, input_query_bbox, attn_mask, mask_dict
"""
if training:
# targets 是 List[dict],代表1個 batch 的標籤,其中每個 dict 是每張圖的標籤
# scalar 代表的是 dn groups,去噪的組數,默認是 5
targets, scalar, label_noise_scale, box_noise_scale, num_patterns = dn_args
else:
num_patterns = dn_args
if num_patterns == 0:
num_patterns = 1
''' 原始 DETR 匹配任务的 content & position queries '''
# content 部分
# 用於指示匹配(matching)任務的向量
indicator0 = torch.zeros([num_queries * num_patterns, 1]).cuda()
# label_enc 是 nn.Embedding(),其 weight 的 shape 是 (num_classes+1, hidden_dim-1)
# 第一維之所以是 num_classes+1 是因為以下 tgt 的初始化值是 num_classes,因此要求 embedding 矩陣的第一維必須有 num_classes+1;
# 而第二維之所以是 hidden_dim-1 是因為要留一個位置給以上的 indicator0
# 由于去噪任务的 label noise 是在 gt label(0~num_classes-1) 上加噪,
# 因此这里 tgt 的初始化值是 num_classes,代表 non-object,以区去噪任(dn)务和匹配(matching)任务
# (hidden_dim-1,)->(num_queries*num_patterns,hidden_dim-1)
tgt = label_enc(torch.tensor(num_classes).cuda()).repeat(num_queries * num_patterns, 1)
# (num_queries*num_patterns,hidden_dim)
tgt = torch.cat([tgt, indicator0], dim=1)
# position 部分
# (num_queries,4)->(num_query*num_patterns,4)
refpoint_emb = embedweight.repeat(num_patterns, 1)