Title page

会议:暂无
年份:2022
github链接:https://github.com/IDEACVR/MaskDINO
pdf链接:https://arxiv.org/abs/2206.02777
Summary
- We present Mask DINO, a unified object detection and segmentation framework. Mask DINO extends DINO (DETR with Improved Denoising Anchor Boxes) by adding a mask prediction branch
- It makes use of the query embeddings from DINO to dot product a high-resolution pixel embedding map to predict a set of binary masks. Some key components in DINO are extended for segmentation through a shared architecture and training process.
- DINO takes advantage of the dynamic anchor box formulation from DAB-DETR and query denoising training from DN-DETR [17], and further achieves the SOTA result on the COCO object detection leaderboard for the first time as a DETR-like model.
- Mask DINO is simple, efficient, and scalable, and it can benefit from joint large-scale detection and segmentation datasets.
Workflow
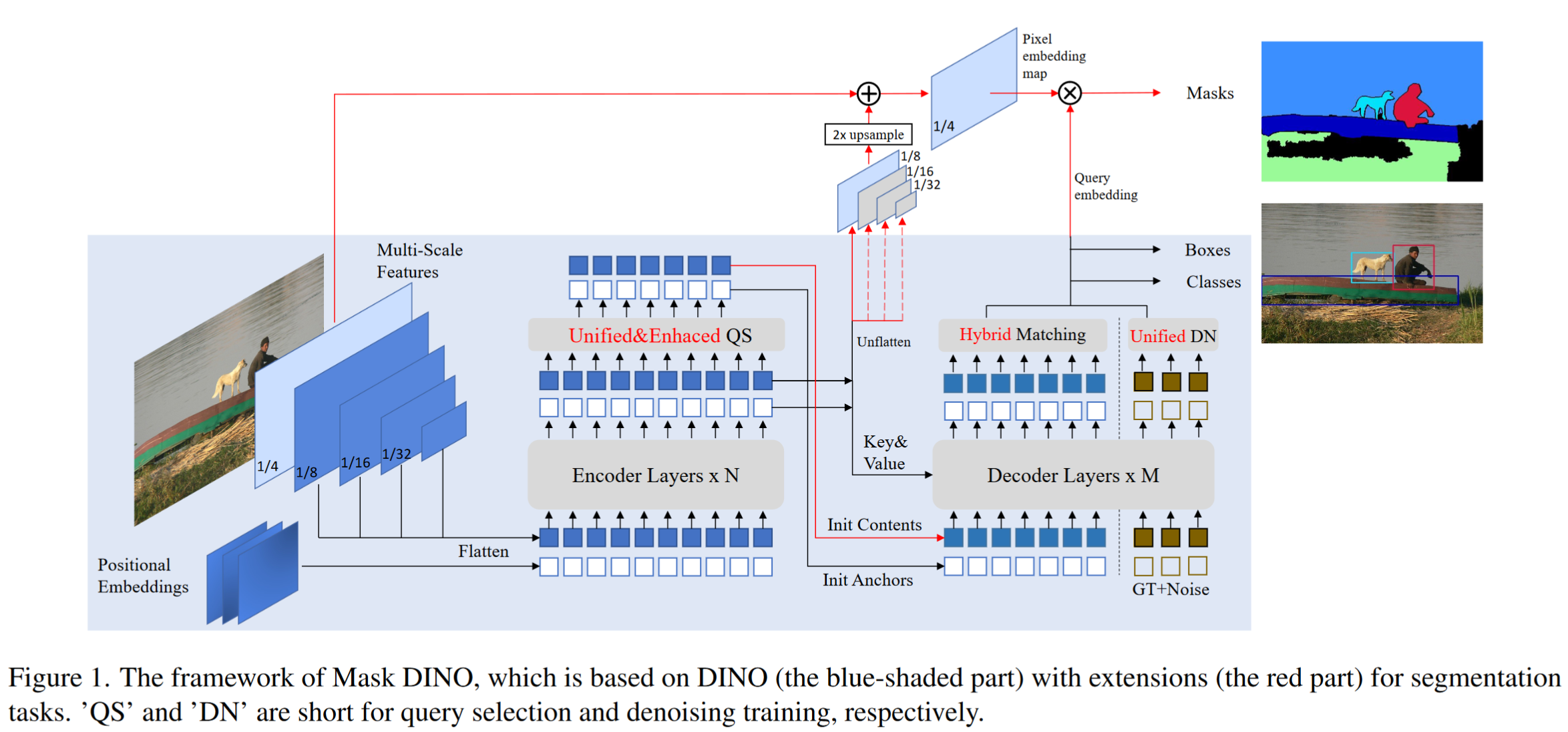
We reuse content query embeddings from DINO to perform mask classification for all segmentation tasks on a high-resolution pixel embedding map (1/4 of the input image resolution) obtained from the backbone and Transformer encoder features.
- The mask branch predicts binary masks by simply dot-producting each content query embedding with the pixel embedding map
- To better align features between detection and segmentation, we also propose three key components to boost the segmentation performance
- a unified and enhanced query selection (utilize encoder dense prior by predicting masks from the top-ranked tokens to initialize mask queries as anchors). We observe that pixel-level segmentation is easier to learn in the early stage and propose to use initial masks to enhance boxes
- a unified denoising training for masks to accelerate segmentation training
- a hybrid bipartite matching for more accurate and consistent matching from ground truth to both boxes and masks
Introduction
-
Although DETR addresses both the object detection and panoptic segmentation tasks, its segmentation performance is still inferior to classical segmentation models.
-
the results of simply using DINO for segmentation and using Mask2Former for detection indicate that they can not do other tasks well

How to attain mutual assistance between segmentation and detection has long been an important problem to solve.
Methods
1. Why a universal model has not replaced the specialized models in DETR-like models?
We attempted to simply extend specialized transformer-based models (DINO/Mask2Former ) for other tasks but found that the performance of other tasks lagged behind the original ones by a large margin.
Trivial multi-task training even hurts the performance of the original task.
However, in convolution-based models, it has shown effective and mutually beneficial to combine detection and instance segmentation tasks.
What are the differences between specialized detection and segmentation models
- Image segmentation is a pixel-level classification task, while object detection is a region-level regression task. In DETR-based model, the decoder queries are responsible for these tasks.
- queries in DINO are not designed to interact with such low-level features to learn pixel-level representation. Instead, they encode rich positional information and highlevel semantics for detection.
Why cannot Mask2Former do detection well?
- its queries follow the design in DETR [1] without being able to utilize better positional priors. For example, its content queries are semantically aligned with the features from the Transformer encoder, whereas its positional queries are just learnable vectors as in vanilla DETR instead of being associated with a singlemode position 1. If we remove its mask branch, it reduces to a variant of DETR
- Mask2Former adopts masked attention (multi-head attention with attention mask) in Transformer decoders. The attention masks predicted from a previous layer are of high resolution and used as hard-constraints for attention computation. They are neither efficient nor flexible for box prediction.
- Mask2Former cannot explicitly perform box refinement layer by layer.
Why cannot DETR/DINO do segmentation well
- DETR’s segmentation head is not optimal.
- Features in improved detection models are not aligned with segmentation. DINO inherits many designs from like query formulation, denoising training, and query selection. However, these components are designed to strengthen region-level representation for detection, which is not optimal for segmentation.
2. Our Method: Mask DINO
Segmentation branch
-
To perform mask classification, we adopt a key idea from Mask2Former to construct a pixel embedding map which is obtained from the backbone and Transformer encoder features.
- the pixel embedding map is obtained by fusing the 1/4 resolution feature map Cb from the backbone with an upsampled 1/8 resolution feature map Ce from the Transformer encoder.
-
Then we dot-product each content query embedding qc from the decoder with the pixel embedding map to obtain an output mask m.
\[m = q_c ⊗ M(T (Cb) + F (Ce)), (1)\]where M is the segmentation head, T is a convolutional layer to map the channel dimension to the Transformer hidden dimension, and F is a simple interpolation function to perform 2x upsampling of Ce
Unified and Enhanced Query Selection
Unified query selection for mask
We adopt three prediction heads (classification, detection, and segmentation) in the encoder output.
Note: The three heads are identical to the decoder heads.
The classification score of each token is considered as the confidence to select top-ranked features and feed them to the decoder as content queries.(DINO 没有这一步初始化)
对initial anchors的优化:The selected features also regress boxes and dot-product with the high-resolution feature map to predict masks. The predicted boxes and masks will be supervised by the ground truth and are considered as initial anchors for the decoder.
Mask-enhanced anchor box initialization
image segmentation is a pixel-level classification task while object detection is a region-level position regression task → it is easier to learn in the initial stage → in the initial stage after unified query selection, mask prediction is much more accurate than box → after unified query selection, we derive boxes from the predicted masks as better anchor box initialization for the decoder.
Segmentation Micro Design
Unified denoising for mask
As masks can be viewed as a more finegrained representation of boxes, box and mask are naturally connected. Therefore, we can treat boxes as a noised version of masks, and train the model to predict masks given boxes as a denoising task. The given boxes for mask prediction are also randomly noised for more efficient mask denoising training.
Hybrid matching
As in some traditional models, predicts boxes and masks with two parallel heads in a loosely coupled manner. → box和mask可能匹配不一致 →
We add a mask prediction loss to encourage more accurate and consistent matching results for one query
Decoupled box prediction
In our hybrid matching, the box loss for “stuff” is set to the mean of “thing” categories. This decoupled design can accelerate training and yield additional gains for panoptic segmentation.
Result-show
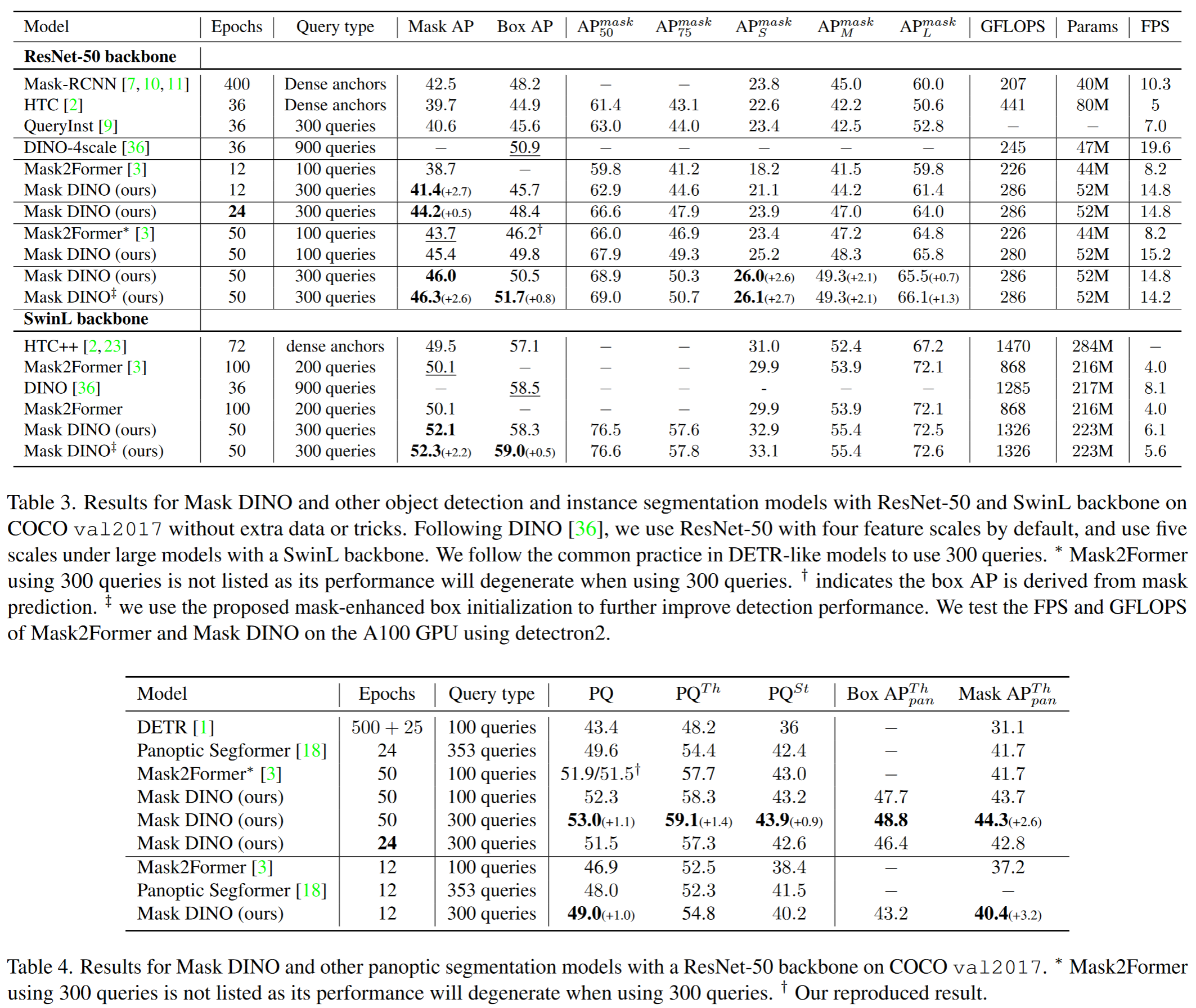
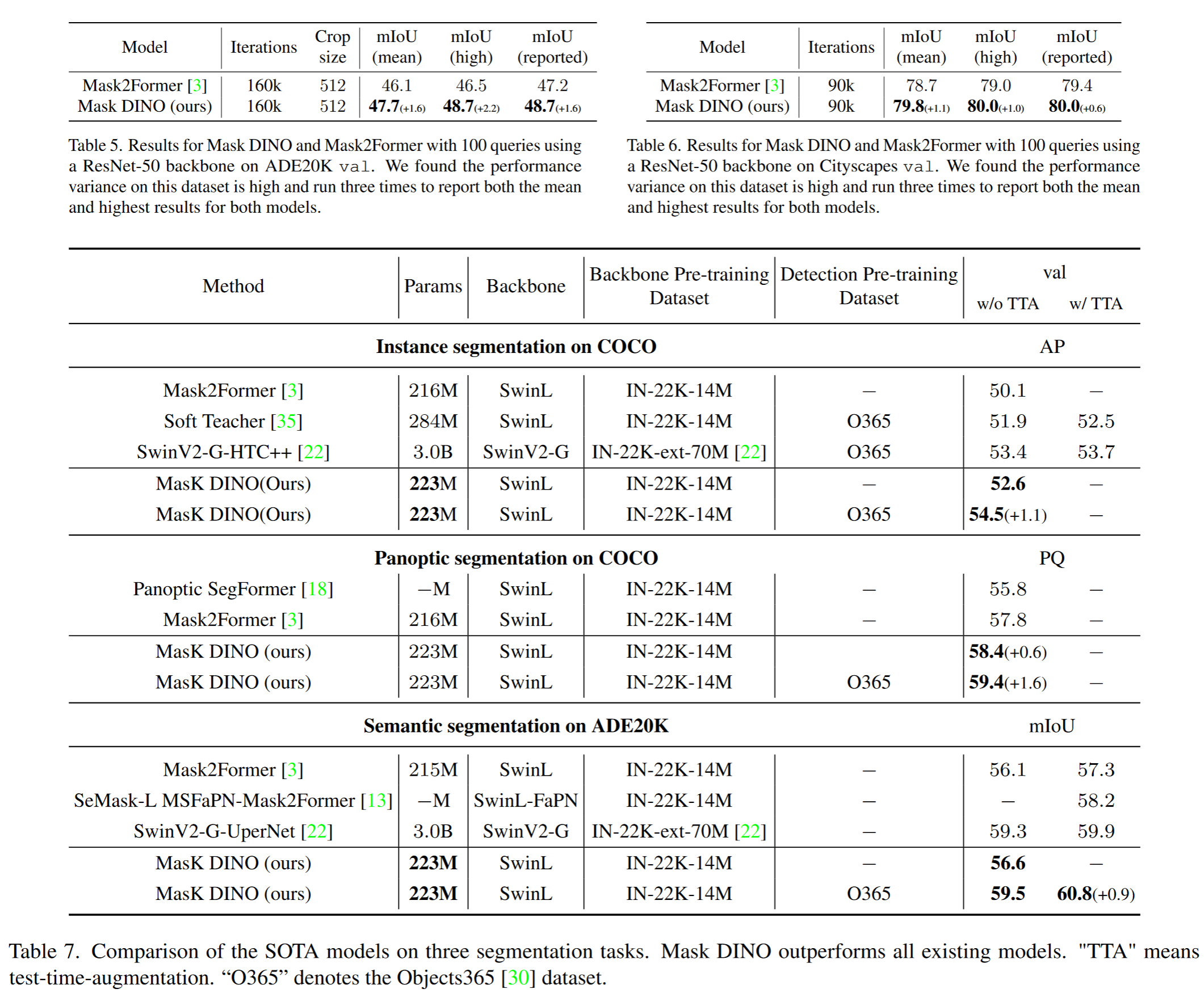
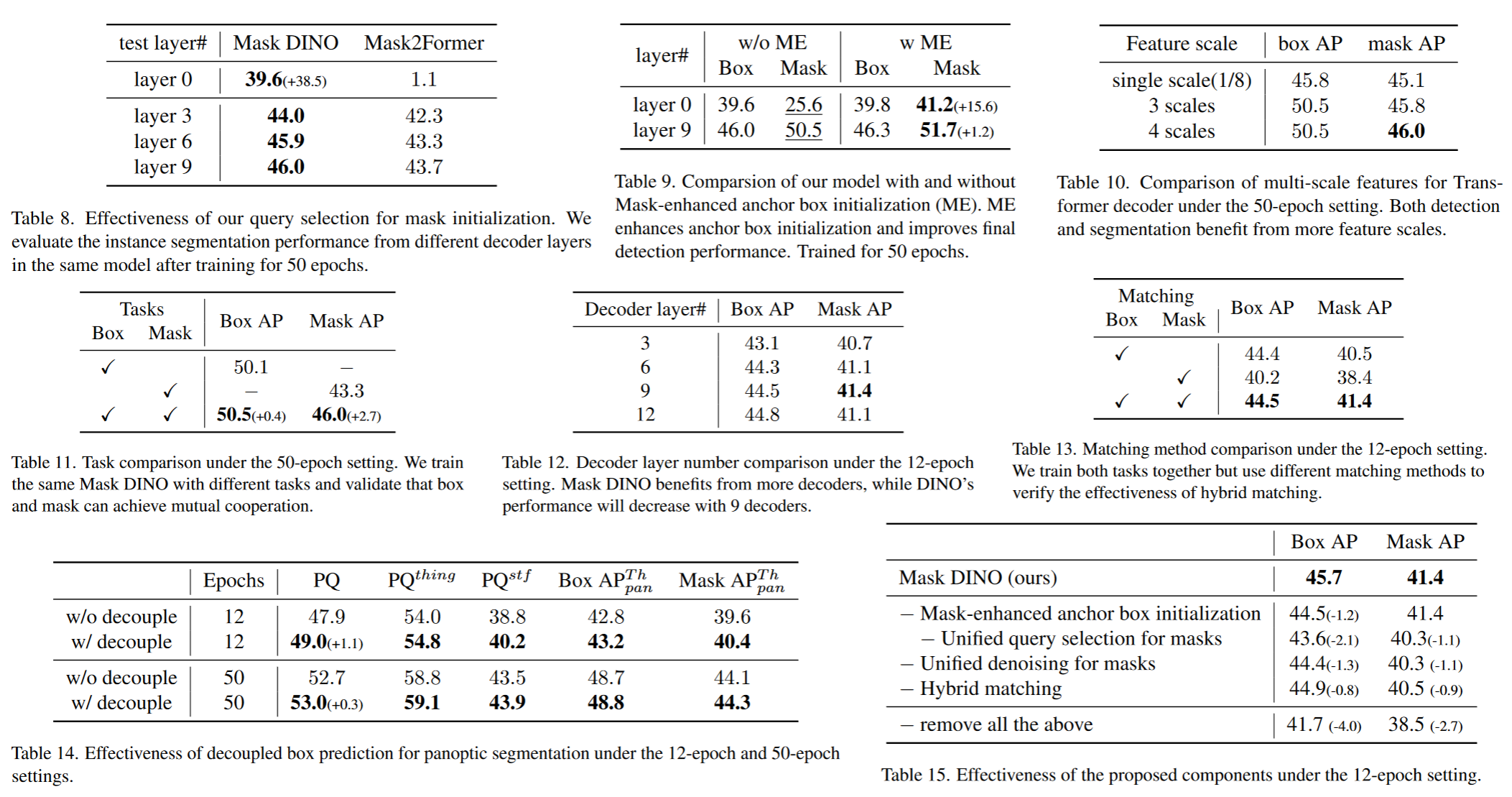
启发和思考
代码注释
1