Title page

会议:Accepted at CVPR 2022
年份:2022
github链接:https://bowenc0221.github.io/mask2former
pdf链接:https://arxiv.org/abs/2112.01527
Summary
-
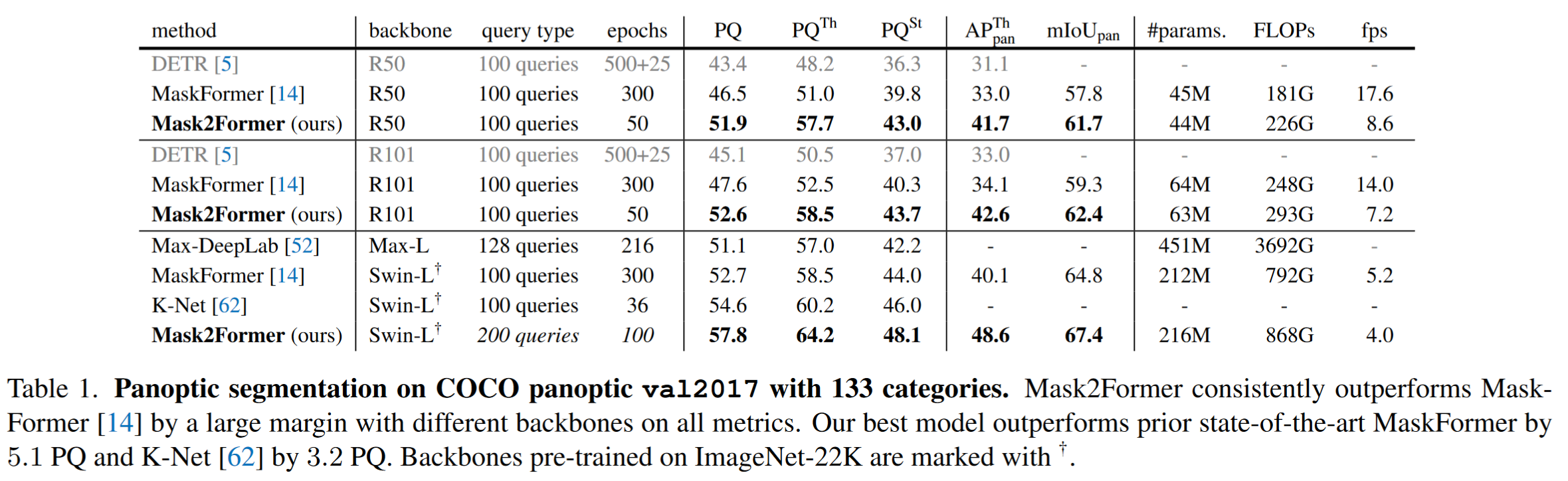
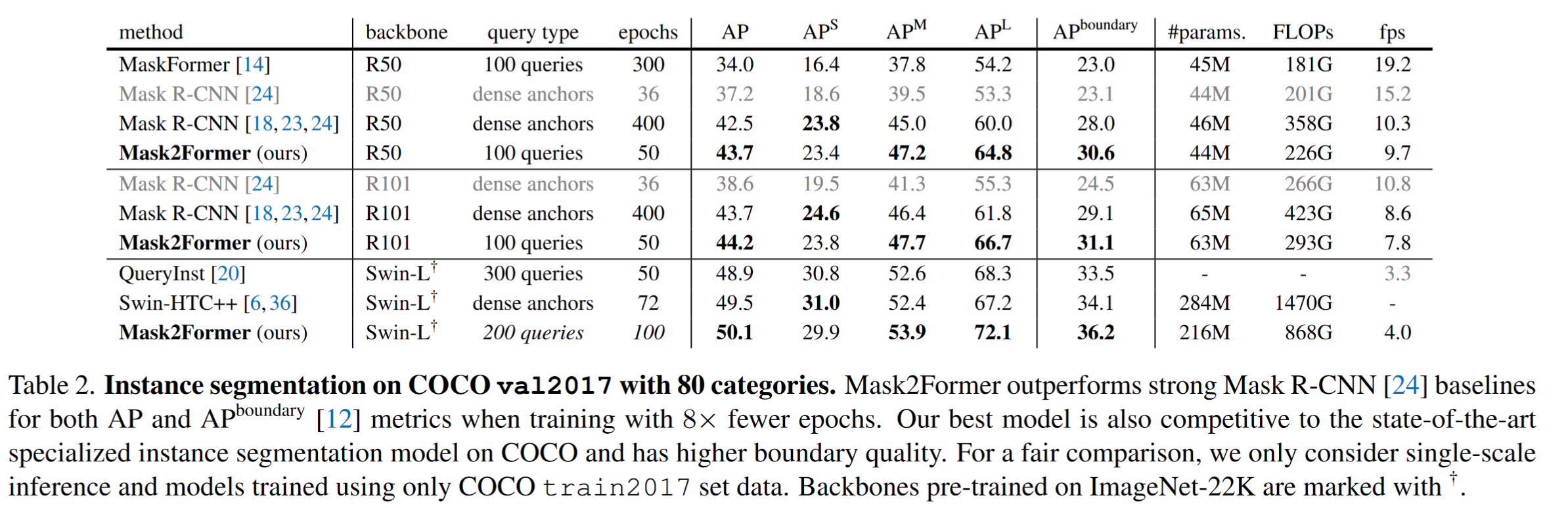
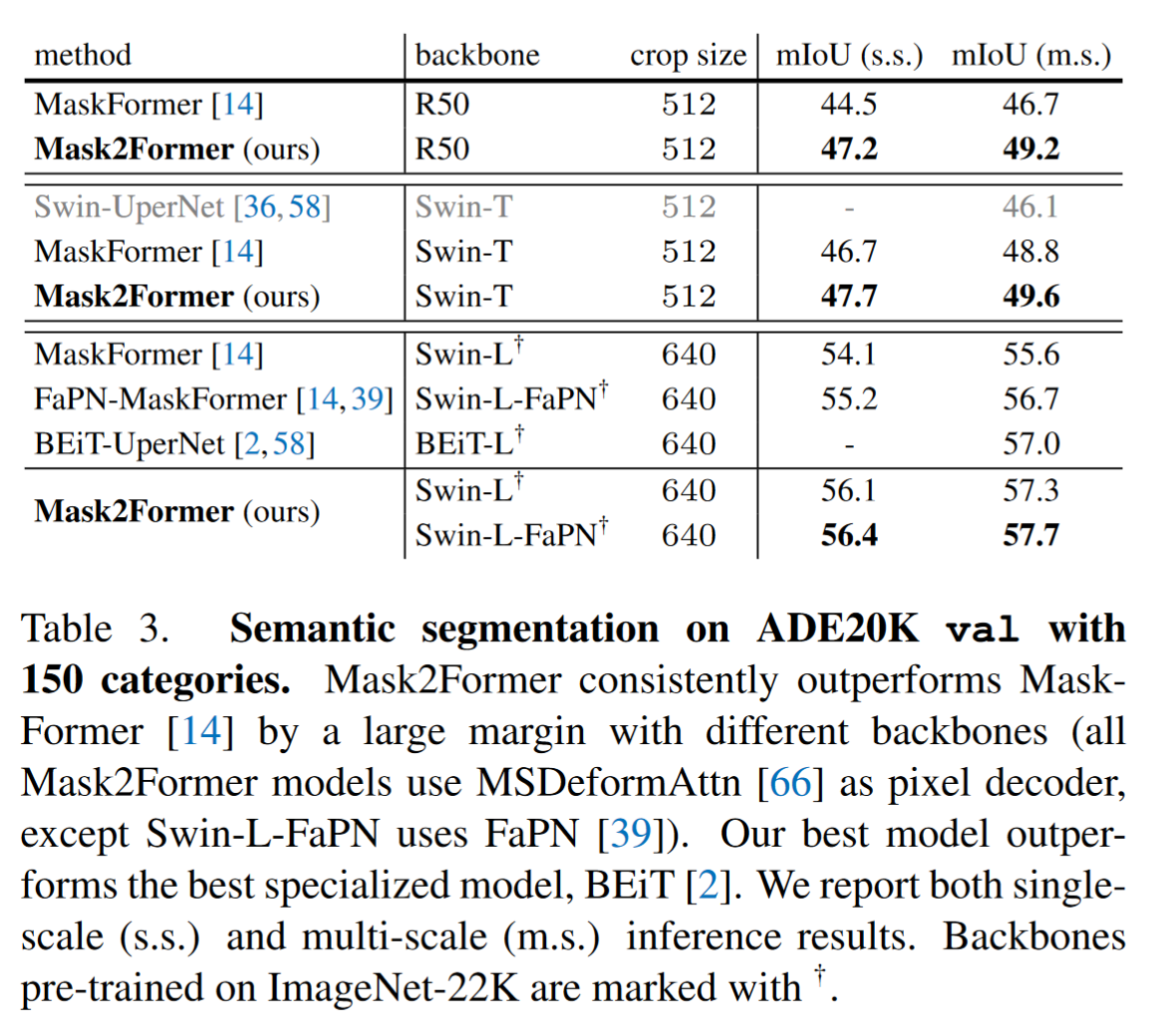
图像分割包括了语义分割(常基于FCNs)、实例分割(mask classification结构,如detr, mask-rcnn)与全景分割,作者提出了一种基于DETR的universal architectures。相较于其他的通用架构,Mask2Former超越了specialized architecture SOTA模型的性能,并且更容易训练(Both the performance and training efficiency issues hamper the deployment of universal architectures.)
-
We build upon a simple meta architecture consisting of a backbone feature extractor, a pixel decoder and a Transformer decoder.
-
关键改进:
-
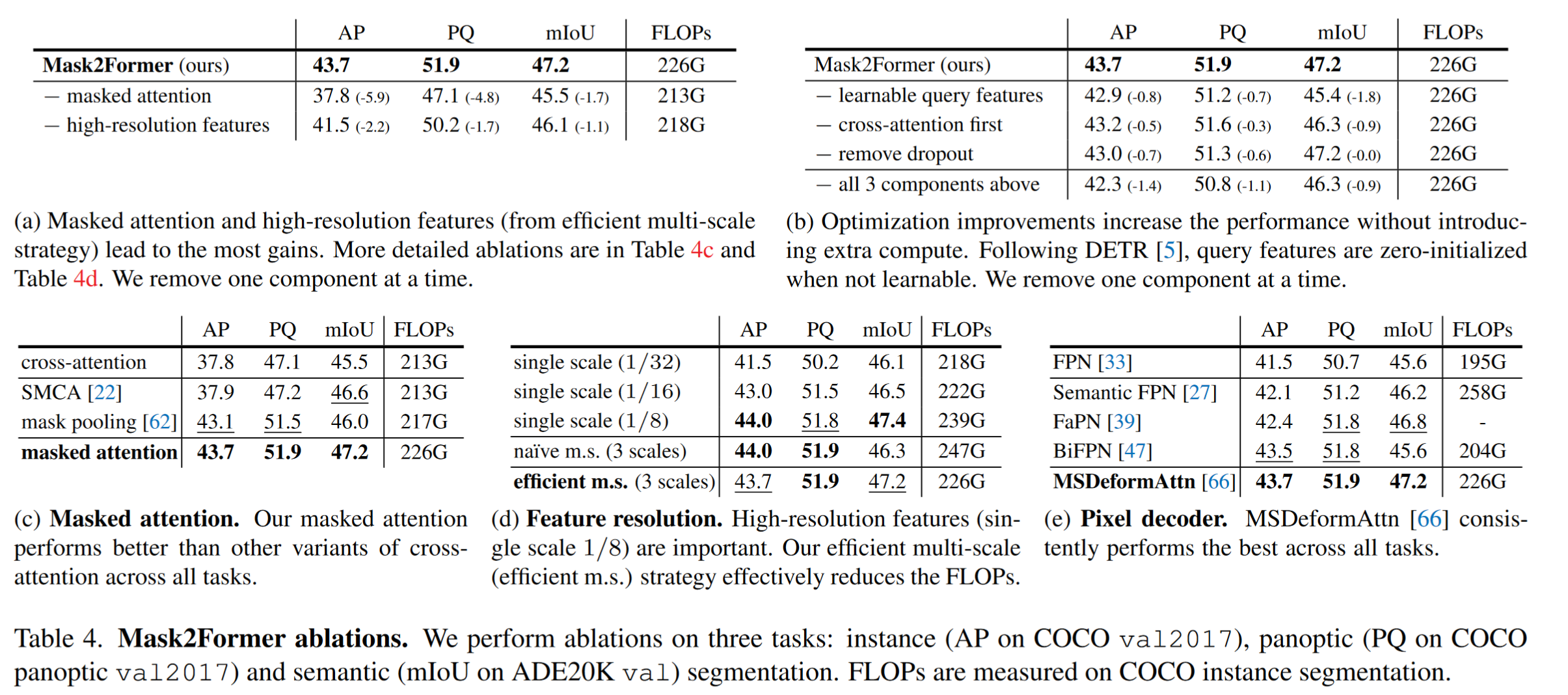
masked attention in the Transformer decoder, which restricts the attention to localized features centered around predicted segments, leading to faster convergence and improved performance.
-
Use multi-scale high-resolution features which help the model to segment small objects/regions.
-
we propose optimization improvements such as switching the order of self and cross-attention, making query features learnable, and removing dropout
-
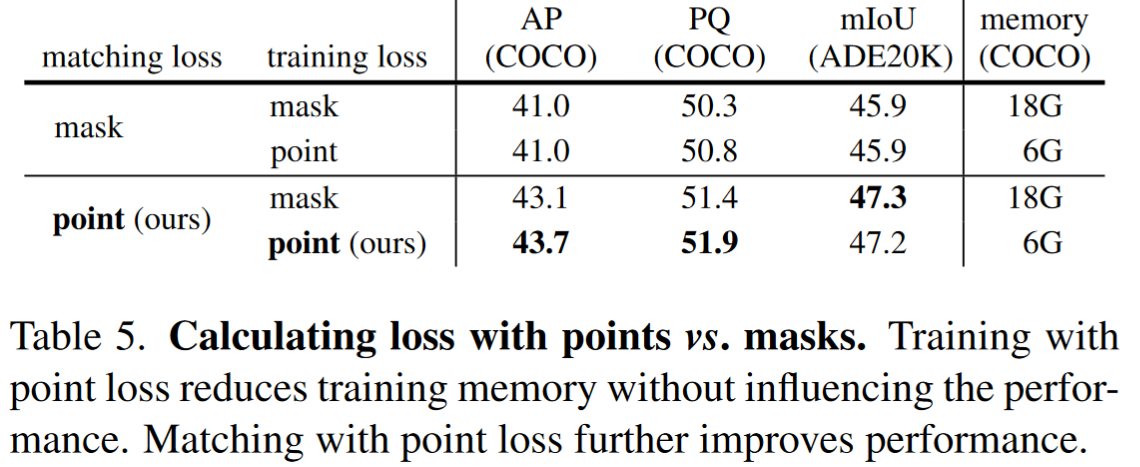
save 3× training memory without affecting the performance by calculating mask loss on few randomly sampled points.
-
Workflow
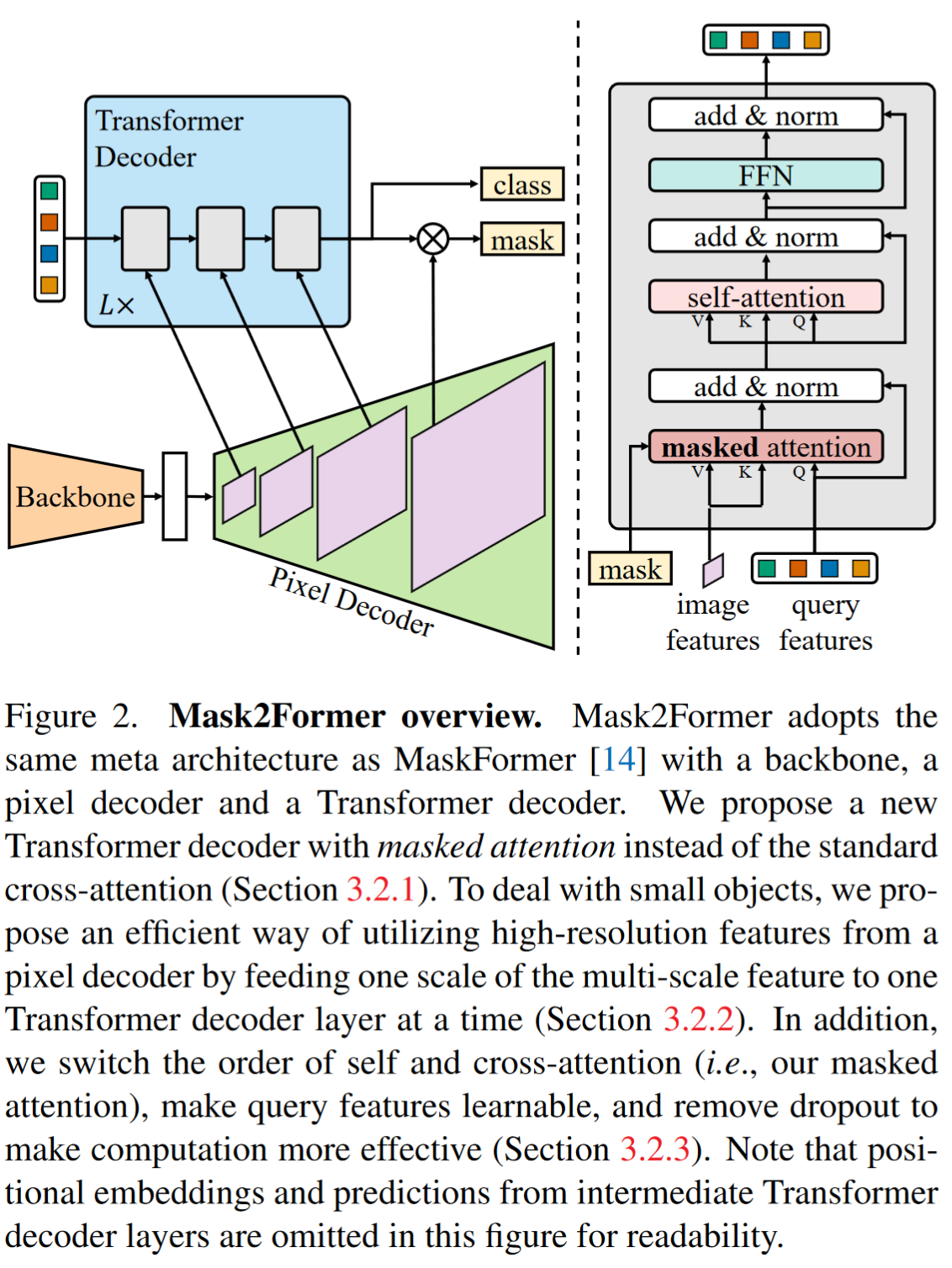
- Pixel decoder: 6 multi-scale deformable attention Transformer (MSDeformAttn) layers applied to feature maps with resolution 1/8, 1/16 and 1/32, and use a simple upsampling layer with lateral connection on the final 1/8 feature map to generate the feature map of resolution 1/4 as the per-pixel embedding.
- Transformer decoder: 详见methods
Methods
1. Mask classification preliminaries
- Mask classification architectures group pixels into N segments by predicting N binary masks, along with N corresponding category labels.
- Inspired by DETR, each segment in an image can be represented as a C-dimensional feature vector (“object query”) and can be processed by a Transformer decoder, trained with a set prediction objective.
- meta architecture
- A backbone
- A pixel decoder that gradually upsamples low-resolution features from the output of the backbone to generate high-resolution per-pixel embeddings.
- a Transformer decoder that operates on image features to process object queries.
- The final binary mask predictions are decoded from per-pixel embeddings with object queries.
2. masked attention
-
最近研究发现,限制DETR收敛的一个重要原因是跨注意力层引入了global context,从而使得cross-attention层需要训练很多轮才能注意到object局部区域。因此作者在解码器中,使用了masked attention 操作子, which extracts localized features by constraining cross attention to within the foreground region of the predicted mask for each query
-
假设:局部特征已足够来更新query的特征,全局信息可以通过自注意力来聚集
-
标准的cross-attention (with residual path)

-
masked-attention

3. High-resolution features
Instead of always using the high-resolution feature map, we utilize a feature pyramid which consists of both low- and high-resolution features and feed one resolution of the multi-scale feature to one Transformer decoder layer(三层特征 → 解码器中对应3层) at a time

4. Optimization improvements
- switch the order of self- and cross-attention to make computation more effective
- we make query features ($X_0$) learnable as well (we still keep the learnable query positional embeddings), and learnable query features are directly supervised before being used in the Transformer decoder to predict masks (M0) —— 作者认为这类似与RPN
- 删除了decoder中的dropout层
- mask loss的计算,使用了随机采样的方法采样了12544(112×112)个点进行计算
Result-show