Title page

会议:Accepted at ICLR 2021
年份:2021 Oral
github链接:https:// github.com/fundamentalvision/Deformable-DETR
pdf链接:http://arxiv.org/abs/2010.04159
Summary
- DETR有完全的端到端特性,但由于Transformer的注意力模块限制,DETR具有两个缺点
- 收敛慢(COCO 500 epochs)
- 限制了空间分辨率
- 作者提出了Deformable DETR,其注意力模块(多尺度可变形卷积注意力模块)只关注了参考位置(reference)附近的一小组关键(key)采样点
- Deformable DETR实现了相较于DETR更好的性能(特别是小物体),并且让训练时间缩短了十倍以上
Workflow
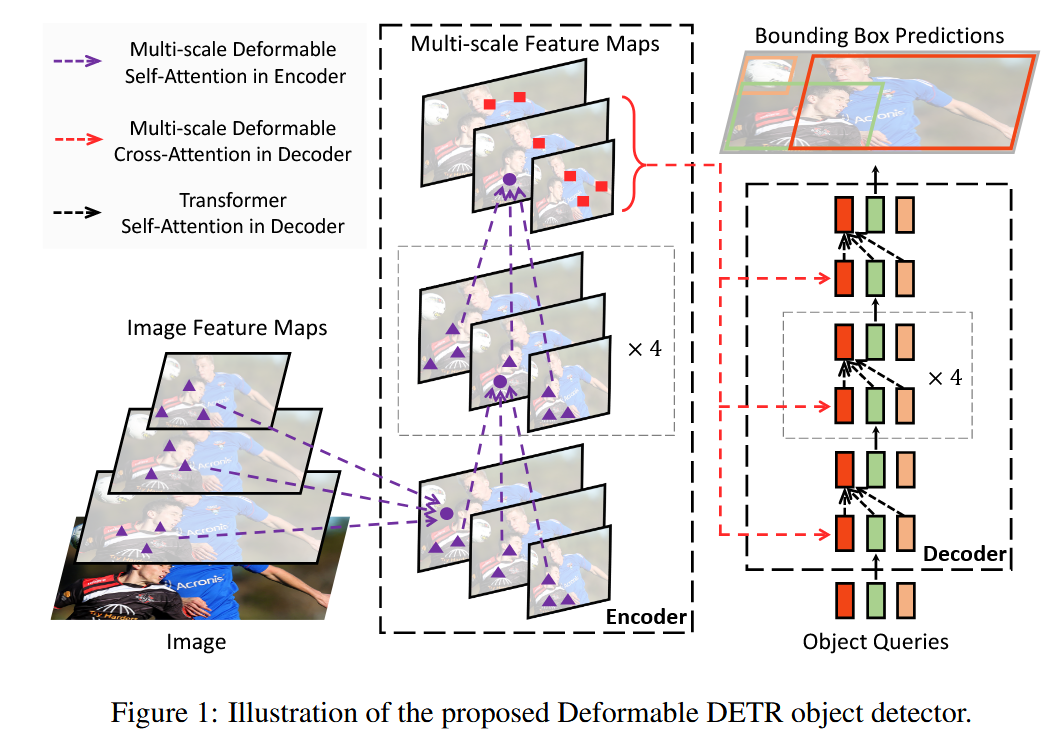
Methods
1. Related Work
Efficient attention mechanism
Transformer引入了自注意力与跨注意力机制(cross-attention),但是时间与内存复杂度非常巨大,目前的三种改进模式
- To use pre-defined sparse attention patterns on keys
- 将注意力模式限制在局部地区 → 损失了全局信息
- 为了补偿1,attend key elements at fixed intervals to significantly increase the receptive field on keys; allow a small number of special tokens having access to all key elements; add some pre-fixed sparse attention patterns to attend distant key elements directly
- To learn data-dependent sparse attention.【这篇文章的方法】
- To explore the low-rank property in self-attention
Multi-scale Feature Representation for Object Detection
作者提出他们的多尺度deformable attention module可以通过注意力机制自然地聚合多尺度特征,无需FPN(Feature pyramid network)
2. REVISITING TRANSFORMERS AND DETR
Multi-Head Attention in Transformers


多头注意力机制:相较于自注意力机制,将q, k, v分别通过各自的线性变换(Um, Vm, W’m),reshape (C) → (h, C // h),同时最后还加了一层 Wm的线性变换
作者认为,DETR收敛慢的原因之一在于
- Transformer在初始化时,分配给所有特征像素的注意力权重几乎是均等的,这就造成了模型需要长时间去学习关注真正有意义的位置,这些位置应该是稀疏的;
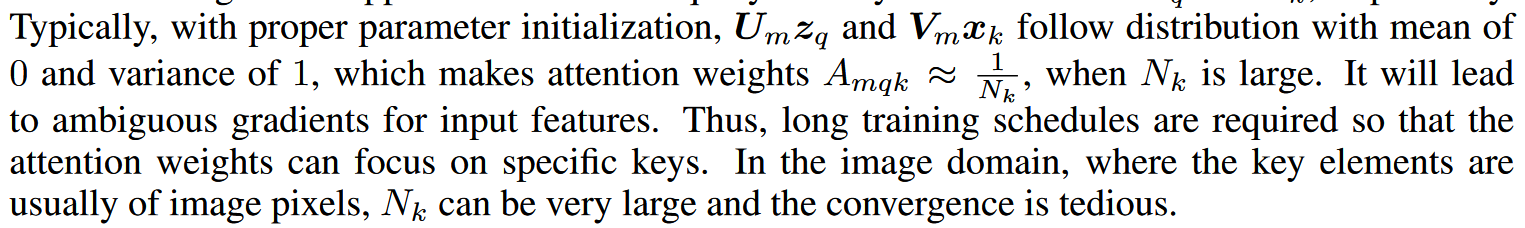
- Transformer在计算注意力权重时,伴随着高计算量与空间复杂度。特别是在编码器部分,与特征像素点的数量成平方级关系O(NqNkC) ,因此难以处理高分辨率的特征(这点也是DETR检测小目标效果差的原因)

DETR
作者分析了DETR的计算复杂度,发现Transformer部分的编码器(自注意力)与图像尺寸呈平方倍率增大;解码器(cross-attention)与feature map尺寸呈线性变化

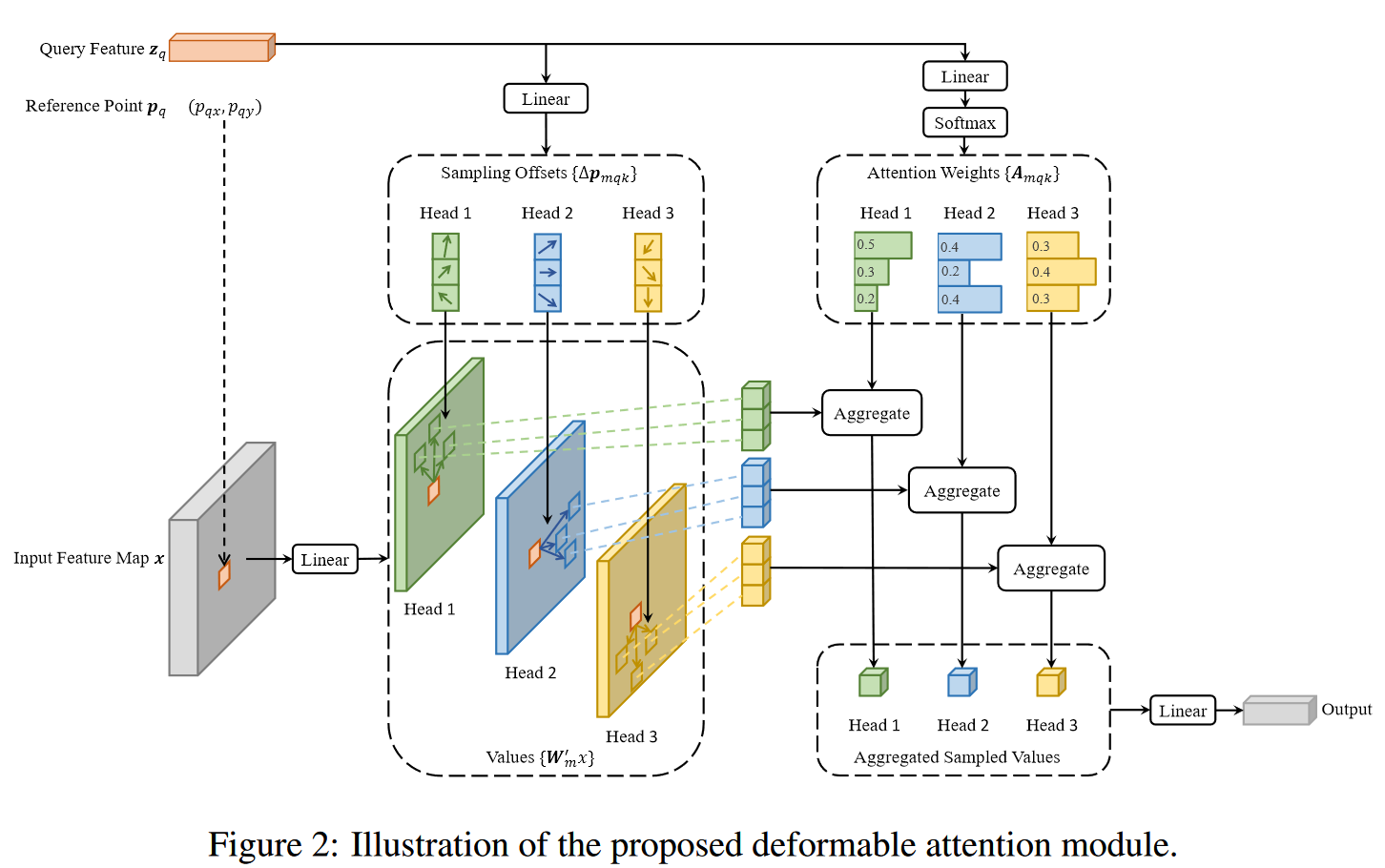
3. Deformable Attention Module.

pq 和 Δpmqk 。其中,前者代表 zq 的位置(理解成坐标即可),是2d向量,作者称其为参考点(reference points);而后者是采样集合点相对于参考点的位置偏移(offsets)。
可以看到,每个query在每个头部中采样K个位置,只需和这些位置的特征交互( x(pq+Δpmqk) 代表基于采样点位置插值出来的value)
复杂度计算:

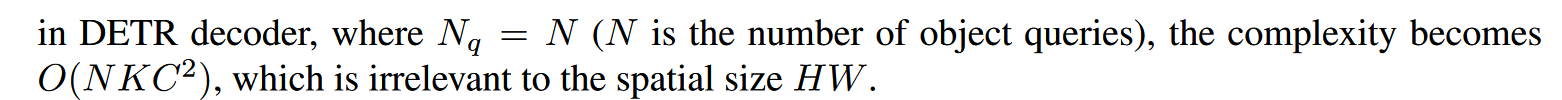
4. Multi-scale Deformable Attention Module

在这里,每个query在每个特征层都会采样K个点,共有L层特征,从而在每个头部内共采样LK个点,注意力权重也是在这LK个点之间进行归一化。
另外,作者还提到,当L=K=1且Wm′ 是identity矩阵时,该模块就退化成可变形卷积;相对地,当采样所有可能的位置(即全局位置)时,该模块等效于Transfomer中的注意力。
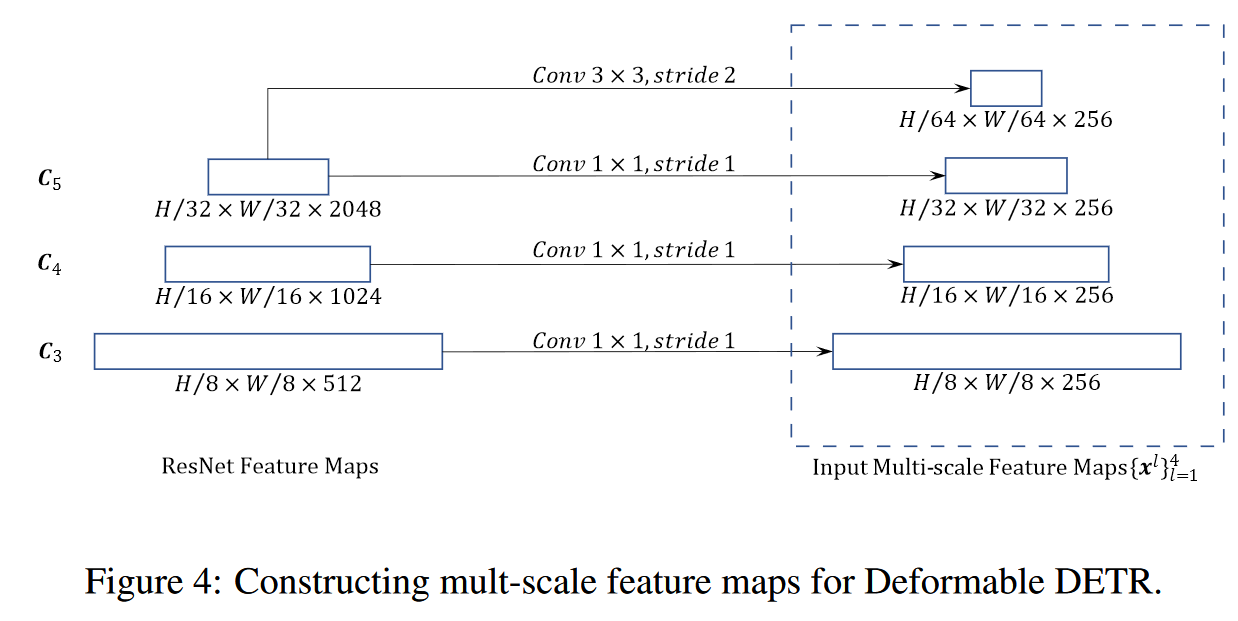
5. Deformable Transformer Encoder
-
We replace the Transformer attention modules processing feature maps in DETR with the proposed multi-scale deformable attention module.
-
Both the input and output of the encoder are of multi-scale feature maps with the same resolutions. In encoder, we extract multi-scale feature maps {xl}L−1 l=1 (L = 4) from the output feature maps of stages C3 through C5 in ResNet (He et al., 2016) (transformed by a 1 × 1 convolution), where Cl is of resolution 2l lower than the input image. The lowest resolution feature map xL is obtained via a 3 × 3 stride 2 convolution on the final C5 stage, denoted as C6. All the multi-scale feature maps are of C = 256 channels.
-
没有使用FPN
6. Deformable Transformer Decoder
只对cross-attention部分使用哦过了multi-scale deformable attention module
-
For each object query, the 2-d normalized coordinate of the reference point $\hat{p}_q$ is predicted from its object query embedding via a learnable linear projection followed by a sigmoid function.
-
The reference point is used as the initial guess of the box center. The detection head predicts the relative offsets w.r.t. (with reference to) the reference point.

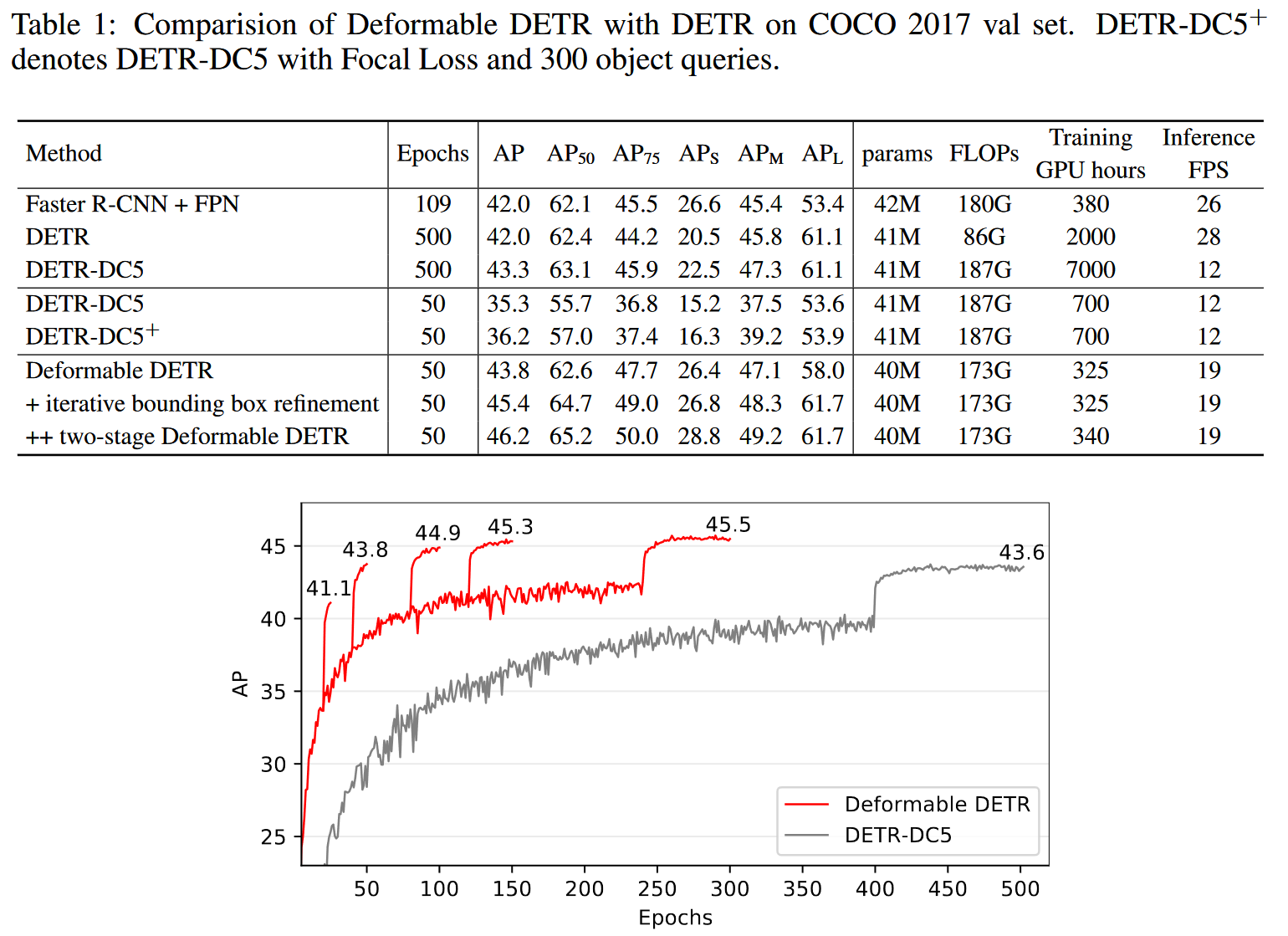
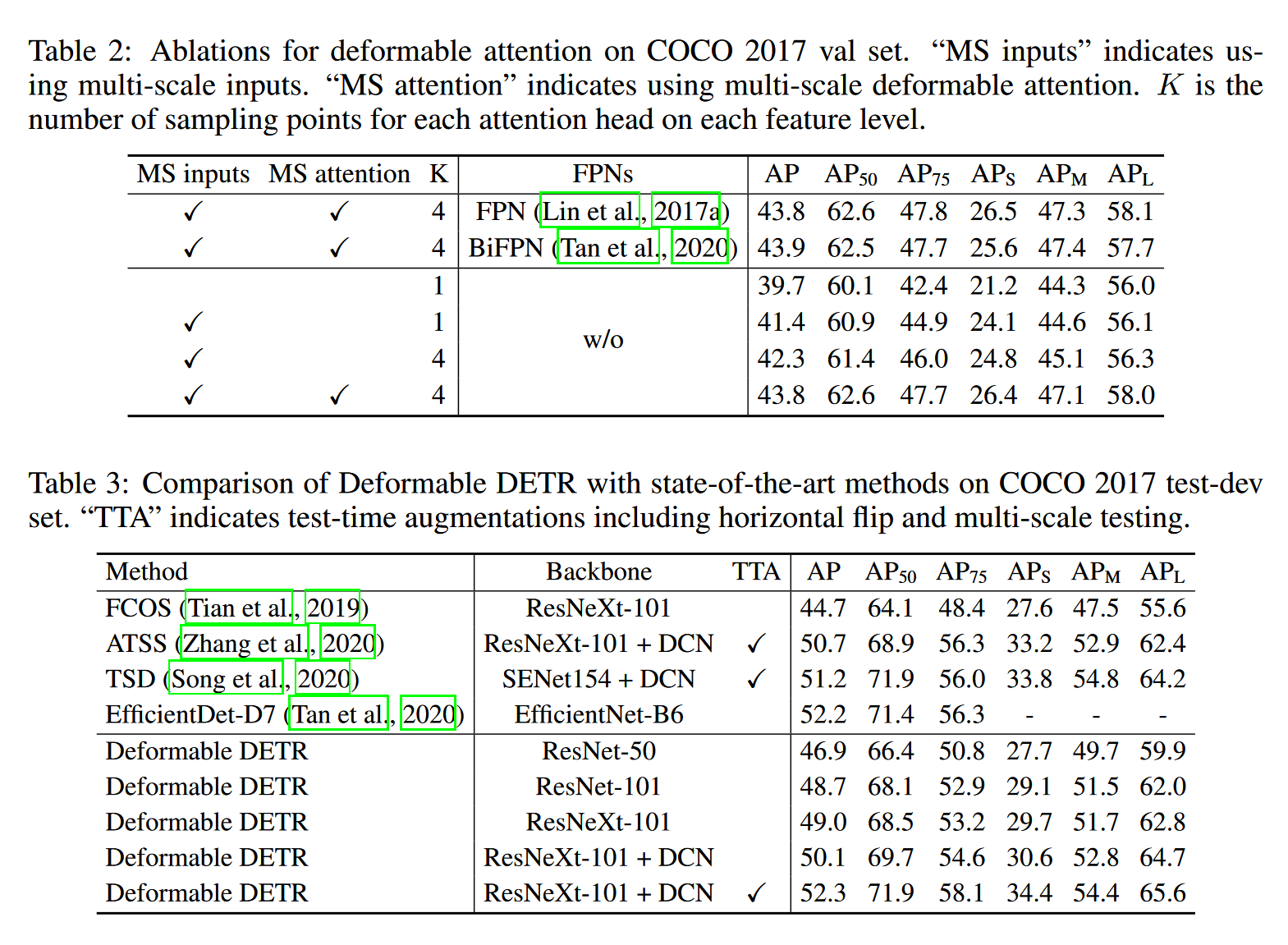
Result-show
启发和思考
代码注释
1