Title page

会议:Accepted at CVPR 2018
年份:2018
github链接:https://github.com/wasidennis/AdaptSegNet
pdf链接:
public: https://arxiv.org/abs/1802.10349
Summary
一种在语义分割中进行域适应的对抗学习方法。通过对output space、多层次的特征进行对抗学习,在不同的特征层面上进行输出空间的域适应,效果较好。
Workflow
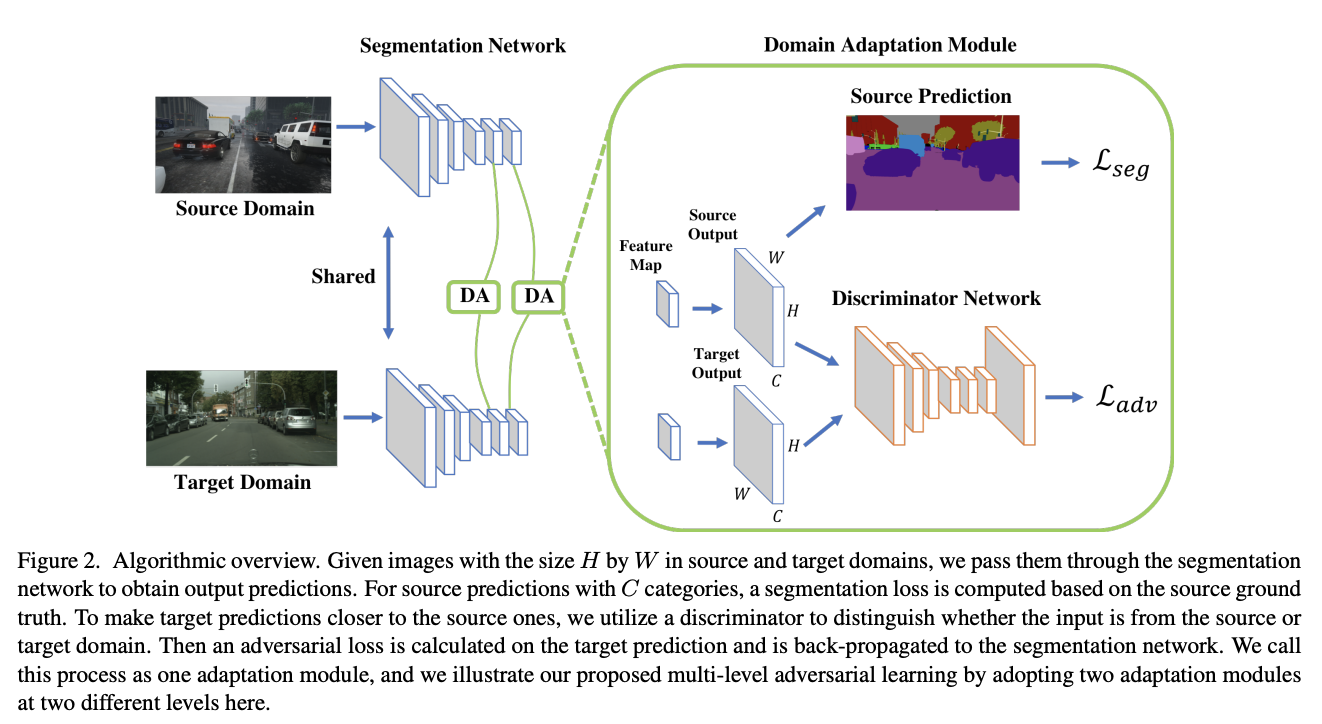
Overview of the proposed model:
- 两个模块:分割网络G和判别器Di,i代表鉴别器所在的层数
- 两种输入:source and target domains are denoted as {\(\mathcal{I_S}\)} and {\(\mathcal{I_T}\)}
- Workflow:
- First forward the source image \(I_s\) (with annotations) to the segmentation network for optimizing \(\mathbf{G}\)
- Then predict the segmentation softmax output \(P_t\) for the target image \(I_t\) (without annotations).
- Use two predictions (\(P_s\), \(P_t\)) as the input to the discriminator \(\mathbf{D_i}\) to distinguish whether the input is from the source or target domain.
- With an adversarial loss on the target prediction, the network propagates gradients from \(\mathbf{D_i}\) to \(\mathbf{G}\),
Methods
Objective Function for Domain Adaptation
- 损失函数:\(\mathcal{L}(I_s, I_t) = \mathcal{L_seg}(Is) + λ_{adv}\mathcal{L_adv}(I_t)\)
- \(\mathcal{L_seg}(Is)\):CE loss,源域计算
- \(\mathcal{L_adv}\):使目标图像的预测分割适应源预测分布的对抗性损失
Output Space Adaptation
与feature space adaption不同
Single-level Adversarial Learning
判别器训练:
- 给定分割 softmax 输出 \(P = \mathbf{G}(I) ∈ \mathbb{R}^{H×W ×C}\) ,其中 C 是类别数
- 使用两个类(source 和 target)的交叉熵损失 \(\mathcal{L_d}\) 将 \(P\) 前向传递给全卷积鉴别器 \(\mathbf{D}\)。

分割网络训练
- 对于source domain的图像:使用正常的交叉熵损失函数计算分割结果

-
对于target domain的图像:尽可能欺骗\(\mathbf{D}\)

Multi-level Adversarial Learning
使用了auxiliary loss进行多层的生成对抗训练,每一层的公式同(3)、(4)


Network Architecture and Training
Discriminator
使用了这篇文章的判别器,但是使用了所有的全卷积层来保留空间信息。该网络由 5 个卷积层组成,内核为 4×4,步长为 2,其中通道数为 {64, 128, 256, 512, 1}。没有使用bn层。
A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016. 2, 4
Segmentation Network
- ImageNet预训练的DeepLab-v2(ResNet-101),但是没有使用多尺度融合策略
- 移除最后一个分类层并将最后两个卷积层的步幅从 2 修改为 1,使输出特征图的分辨率有效地为输入图像大小的 1/8 倍。
- 使用dilated convolution layers增大感受野,最后一层使用ASPP作为最终分类器
- 在Cityscapes上实现了65.1% IoU
Multi-level Adaptation Model
In this paper, we use two levels due to the balance of its efficiency and accuracy.
Network Training
-
使用了联合训练分割网络和判别器的方法
-
每一个训练batch
- Forward the source image \(I_s\) to optimize the segmentation network for \(\mathcal{L_seg}\) in (3) and generate the output \(P_s\)
- For the target image \(I_t\), obtain the segmentation output \(P_t\), and pass it along with \(P_s\) to the discriminator for optimizing \(\mathcal{L_d}\) in (2)
- Compute the adversarial loss \(\mathcal{L_adv}\) in (4) for the target prediction \(P_t\)
- multi-level, simply repeat
-
设备参数:

Result-show
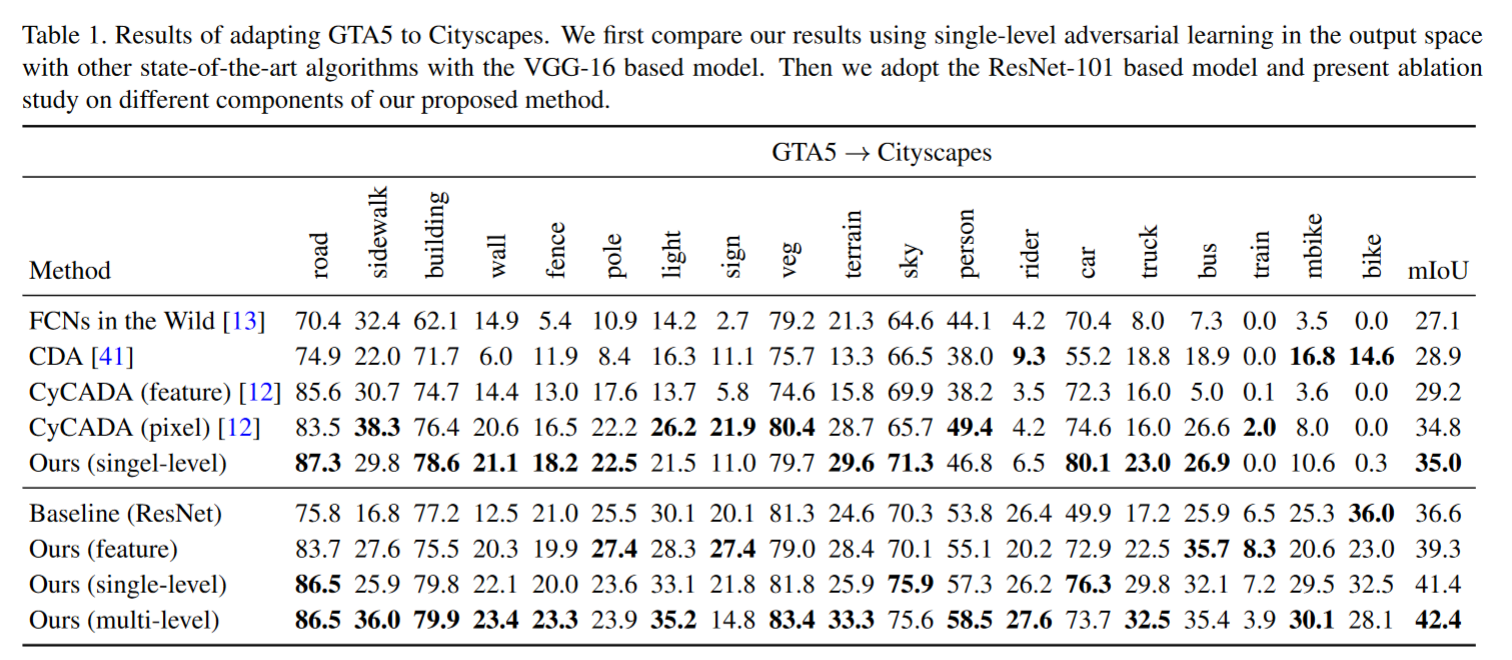
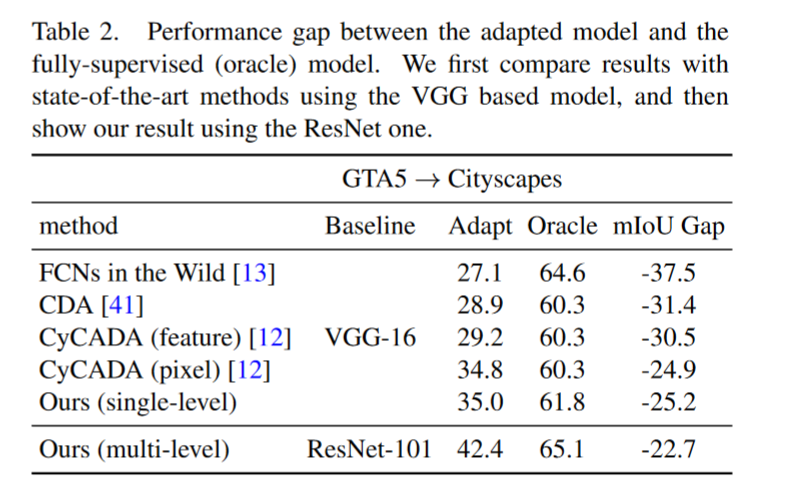
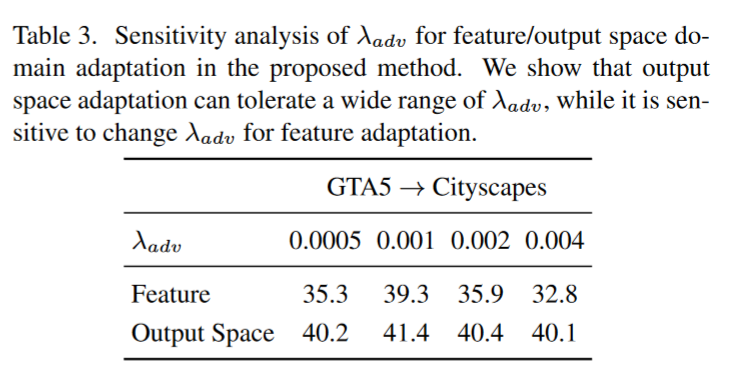
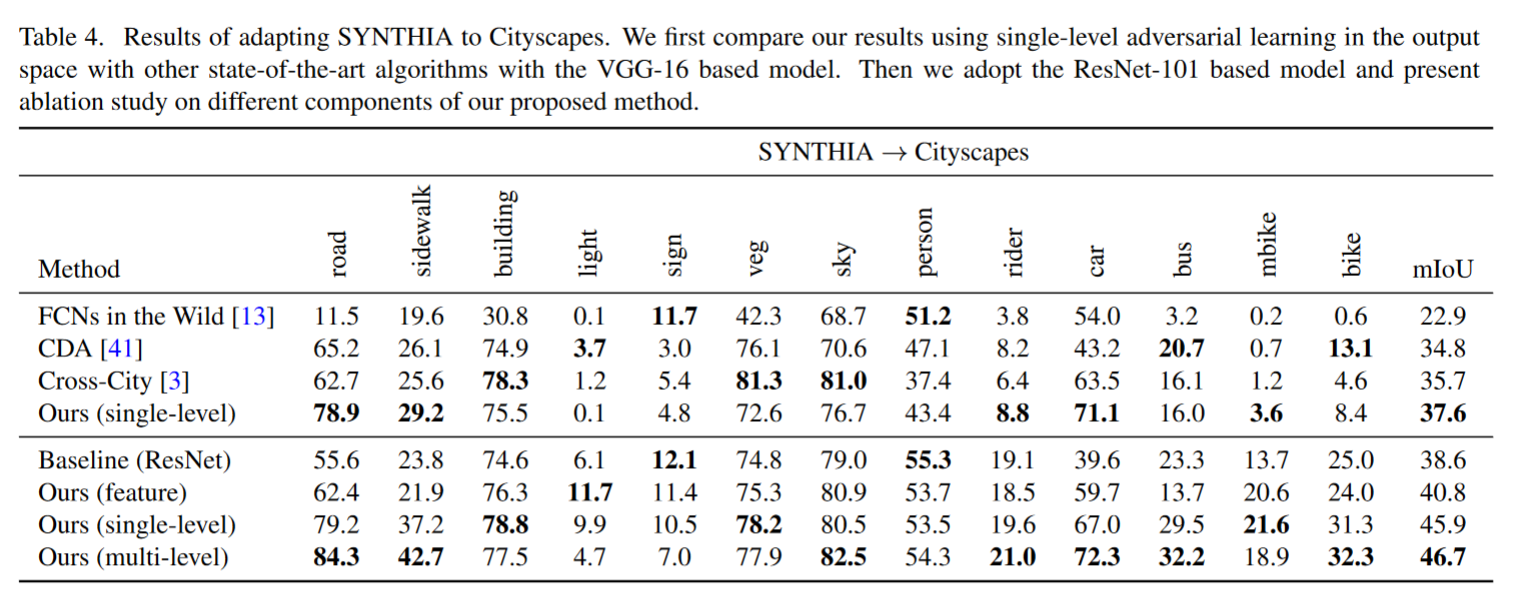
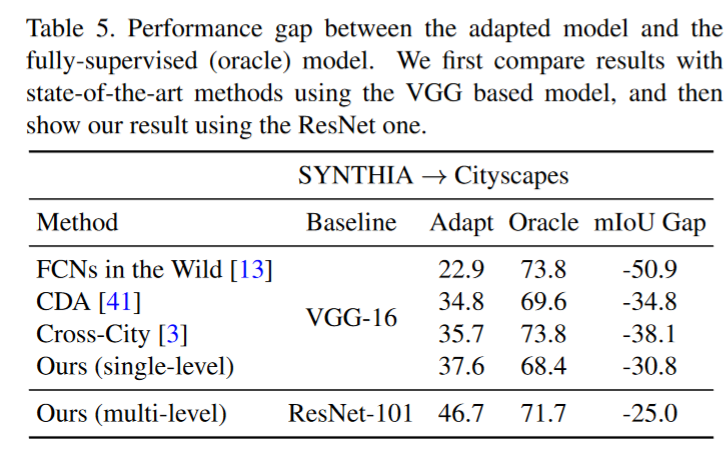
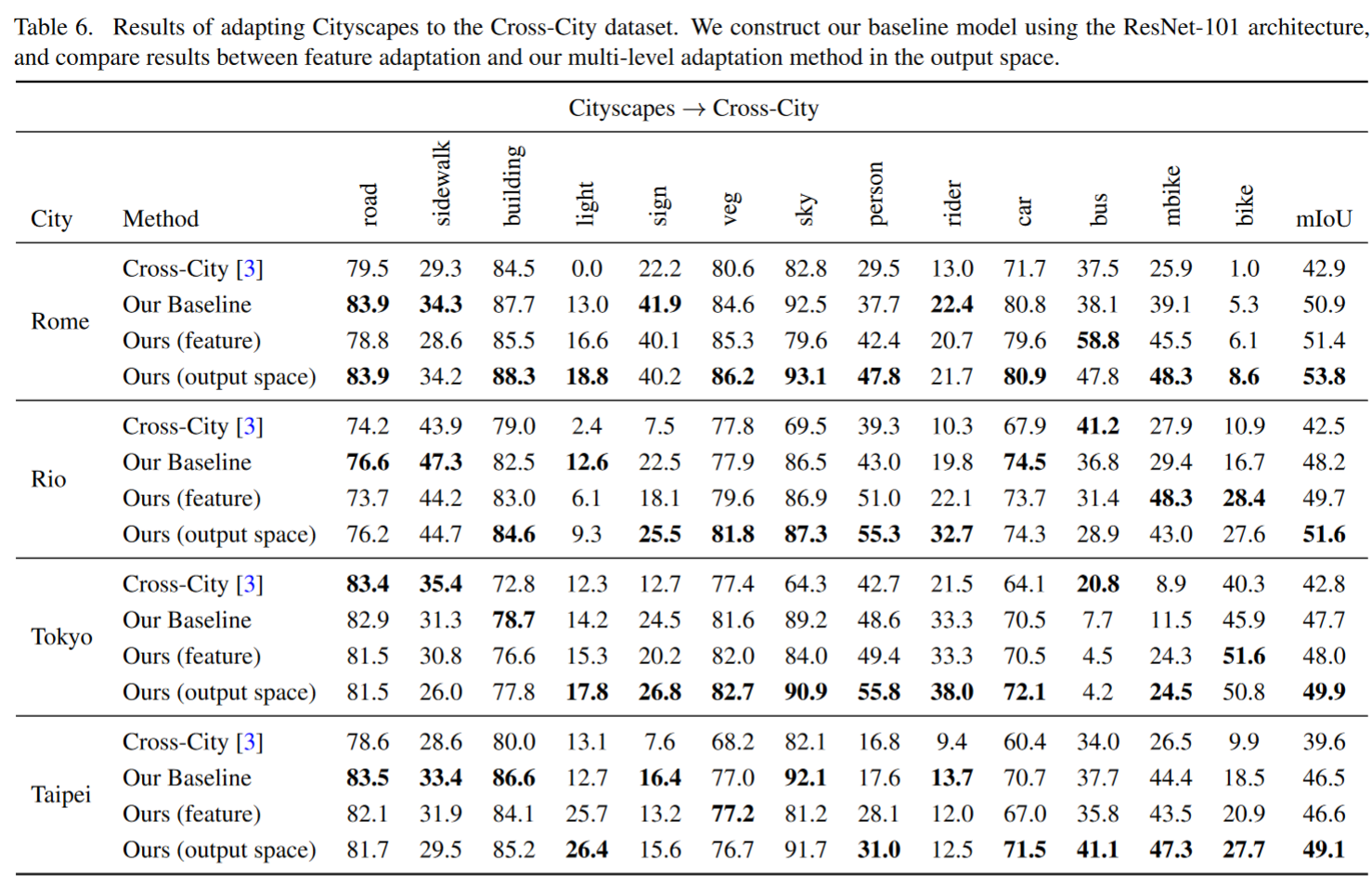

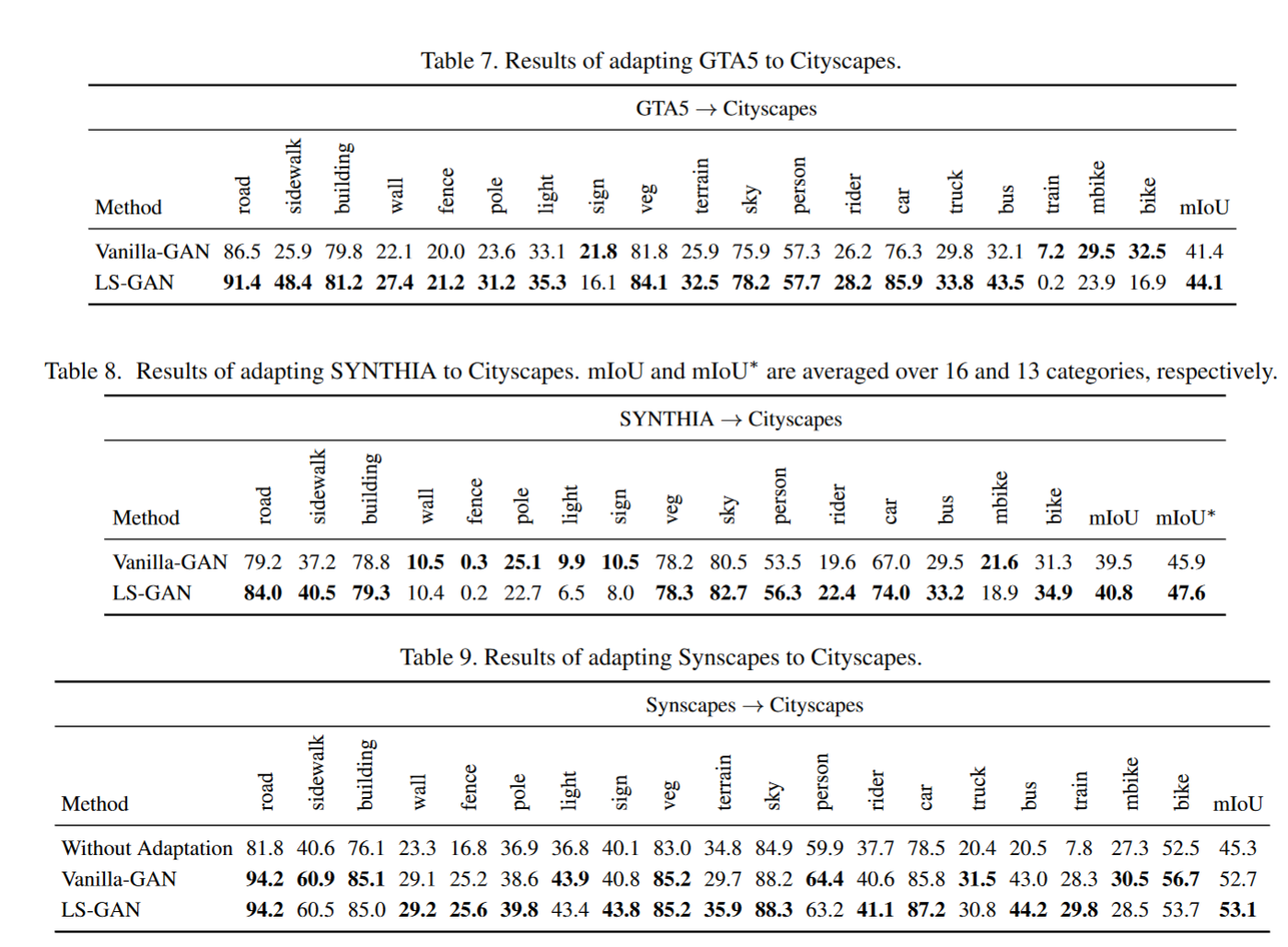
启发和思考
-
肠镜的数据来源及对应的镜头型号、分辨率
来源 图像处理期型号 数量 分辨率 浙二-Pathology Olympus CV-290 3000 720*576 宁波-Pathology Olympus 500 720*576 海宁-Pathology Fujinon 200 656*562 Kvasir-SEG Olympus/Olympus ScopeGuide 1000 各种各样/测试集 CVC-clinicDB 未知 612 384*288 https://www.sciencedirect.com/science/article/pii/S0895611115000567#bib0415 CVC-ColonDB SUN Olympus CV-290 27314 1158*1008 浙二-2021-解放路 Olympus CV-290 23个视频 720*576 浙二-2021-89-城东 Olympus CV-290 200个视频,20000图片 PolypsSet 1. path: /scratch/mfathan/Thesis/Dataset/Extracted/Set1_Frames/… 76 videos or /krushipatel
2. MICCAI2017
3. 80_videos_frame: kumc
4. krushipatelpolydeep NBI(4307+1639张)
WL(8130+1188张)
阴性 14105张768*576
代码注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
### https://github.com/wasidennis/AdaptSegNet/model/discriminator.py
import torch.nn as nn
import torch.nn.functional as F
class FCDiscriminator(nn.Module):
def __init__(self, num_classes, ndf = 64):
super(FCDiscriminator, self).__init__()
self.conv1 = nn.Conv2d(num_classes, ndf, kernel_size=4, stride=2, padding=1)
self.conv2 = nn.Conv2d(ndf, ndf*2, kernel_size=4, stride=2, padding=1)
self.conv3 = nn.Conv2d(ndf*2, ndf*4, kernel_size=4, stride=2, padding=1)
self.conv4 = nn.Conv2d(ndf*4, ndf*8, kernel_size=4, stride=2, padding=1)
self.classifier = nn.Conv2d(ndf*8, 1, kernel_size=4, stride=2, padding=1)
self.leaky_relu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
#self.up_sample = nn.Upsample(scale_factor=32, mode='bilinear')
#self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.conv1(x)
x = self.leaky_relu(x)
x = self.conv2(x)
x = self.leaky_relu(x)
x = self.conv3(x)
x = self.leaky_relu(x)
x = self.conv4(x)
x = self.leaky_relu(x)
x = self.classifier(x)
#x = self.up_sample(x)
#x = self.sigmoid(x)
return x
### https://github.com/wasidennis/AdaptSegNet/blob/master/train_gta2cityscapes_multi.py
# Create network
model = DeeplabMulti()
model.train()
model.cuda(args.gpu)
# init D 使用了两层的Discriminator
model_D1 = FCDiscriminator(num_classes=args.num_classes)
model_D2 = FCDiscriminator(num_classes=args.num_classes)
model_D1.train()
model_D1.cuda(args.gpu)
model_D2.train()
model_D2.cuda(args.gpu)
# Dataloader
trainloader = data.DataLoader(
GTA5DataSet(args.data_dir, args.data_list, max_iters=args.num_steps * args.iter_size * args.batch_size, crop_size=input_size, scale=args.random_scale, mirror=args.random_mirror, mean=IMG_MEAN), batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers, pin_memory=True)
trainloader_iter = enumerate(trainloader)
targetloader = data.DataLoader(cityscapesDataSet(args.data_dir_target, args.data_list_target, max_iters=args.num_steps * args.iter_size * args.batch_size, crop_size=input_size_target, scale=False, mirror=args.random_mirror, mean=IMG_MEAN, set=args.set), batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers, pin_memory=True)
targetloader_iter = enumerate(targetloader)
# optimizer
optimizer = optim.SGD(model.optim_parameters(args), lr=args.learning_rate, momentum=args.momentum, weight_decay=args.weight_decay)
optimizer.zero_grad()
# LEARNING_RATE_D = 1e-4
optimizer_D1 = optim.Adam(model_D1.parameters(), lr=args.learning_rate_D, betas=(0.9, 0.99))
optimizer_D1.zero_grad()
optimizer_D2 = optim.Adam(model_D2.parameters(), lr=args.learning_rate_D, betas=(0.9, 0.99))
optimizer_D2.zero_grad()
if args.gan == 'Vanilla':
bce_loss = torch.nn.BCEWithLogitsLoss()
elif args.gan == 'LS':
bce_loss = torch.nn.MSELoss()
# labels for adversarial training
source_label = 0
target_label = 1
for i_iter in range(args.num_steps):
# 每一步重新清零loss
loss_seg_value1 = 0
loss_adv_target_value1 = 0
loss_D_value1 = 0
loss_seg_value2 = 0
loss_adv_target_value2 = 0
loss_D_value2 = 0
optimizer.zero_grad()
adjust_learning_rate(optimizer, i_iter)
optimizer_D1.zero_grad()
optimizer_D2.zero_grad()
adjust_learning_rate_D(optimizer_D1, i_iter)
adjust_learning_rate_D(optimizer_D2, i_iter)
# args.iter_size: 1
for sub_i in range(args.iter_size):
# train G
# don't accumulate grads in D
for param in model_D1.parameters():
param.requires_grad = False
for param in model_D2.parameters():
param.requires_grad = False
# train with source
_, batch = trainloader_iter.next()
images, labels, _, _ = batch
images = Variable(images).cuda(args.gpu)
# pred1, pred2:
pred1, pred2 = model(images)
# interp = nn.Upsample(size=(input_size[1], input_size[0]), mode='bilinear')
pred1 = interp(pred1)
pred2 = interp(pred2)
# args.lambda_seg = 0.1
loss_seg1 = loss_calc(pred1, labels, args.gpu)
loss_seg2 = loss_calc(pred2, labels, args.gpu)
loss = loss_seg2 + args.lambda_seg * loss_seg1
# proper normalization
loss = loss / args.iter_size
loss.backward()
loss_seg_value1 += loss_seg1.data.cpu().numpy()[0] / args.iter_size
loss_seg_value2 += loss_seg2.data.cpu().numpy()[0] / args.iter_size
# train with target
_, batch = targetloader_iter.next()
images, _, _ = batch
images = Variable(images).cuda(args.gpu)
pred_target1, pred_target2 = model(images)
# interp_target = nn.Upsample(size=(input_size_target[1], input_size_target[0]), mode='bilinear')
pred_target1 = interp_target(pred_target1)
pred_target2 = interp_target(pred_target2)
D_out1 = model_D1(F.softmax(pred_target1))
D_out2 = model_D2(F.softmax(pred_target2))
loss_adv_target1 = bce_loss(D_out1, Variable(torch.FloatTensor(D_out1.data.size()).fill_(source_label)).cuda(
args.gpu))
loss_adv_target2 = bce_loss(D_out2,
Variable(torch.FloatTensor(D_out2.data.size()).fill_(source_label)).cuda(
args.gpu))
loss = args.lambda_adv_target1 * loss_adv_target1 + args.lambda_adv_target2 * loss_adv_target2
loss = loss / args.iter_size
loss.backward()
loss_adv_target_value1 += loss_adv_target1.data.cpu().numpy()[0] / args.iter_size
loss_adv_target_value2 += loss_adv_target2.data.cpu().numpy()[0] / args.iter_size
# train D
# bring back requires_grad
for param in model_D1.parameters():
param.requires_grad = True
for param in model_D2.parameters():
param.requires_grad = True
# train with source
pred1 = pred1.detach()
pred2 = pred2.detach()
D_out1 = model_D1(F.softmax(pred1))
D_out2 = model_D2(F.softmax(pred2))
loss_D1 = bce_loss(D_out1, Variable(torch.FloatTensor(D_out1.data.size()).fill_(source_label)).cuda(args.gpu))
loss_D2 = bce_loss(D_out2, Variable(torch.FloatTensor(D_out2.data.size()).fill_(source_label)).cuda(args.gpu))
loss_D1 = loss_D1 / args.iter_size / 2
loss_D2 = loss_D2 / args.iter_size / 2
loss_D1.backward()
loss_D2.backward()
loss_D_value1 += loss_D1.data.cpu().numpy()[0]
loss_D_value2 += loss_D2.data.cpu().numpy()[0]
# train with target
pred_target1 = pred_target1.detach()
pred_target2 = pred_target2.detach()
D_out1 = model_D1(F.softmax(pred_target1))
D_out2 = model_D2(F.softmax(pred_target2))
loss_D1 = bce_loss(D_out1,
Variable(torch.FloatTensor(D_out1.data.size()).fill_(target_label)).cuda(args.gpu))
loss_D2 = bce_loss(D_out2,
Variable(torch.FloatTensor(D_out2.data.size()).fill_(target_label)).cuda(args.gpu))
loss_D1 = loss_D1 / args.iter_size / 2
loss_D2 = loss_D2 / args.iter_size / 2
loss_D1.backward()
loss_D2.backward()
loss_D_value1 += loss_D1.data.cpu().numpy()[0]
loss_D_value2 += loss_D2.data.cpu().numpy()[0]
optimizer.step()
optimizer_D1.step()
optimizer_D2.step()