Title page

会议:Accepted at
年份:2022.8
github链接:https://github.com/nvlabs/minvis
pdf链接:https://arxiv.org/pdf/2208.02245.pdf
private pdf链接:file:///C:/Users/Seasons/Zotero/storage/8CRJUA95/Huang%20et%20al_2022_MinVIS.pdf
Summary
- 提出了一个视频实例分割框架,可以只使用图像实例分割的数据(1%帧),实现视频实例分割的SOTA
- Key observation: queries trained to be discriminative between intra-frame object instances are temporally consistent and can be used to track instances without any manually designed heuristics.(不同实例的queries可以直接用于实例追踪)
- 推理框架:We first apply the trained query-based image instance segmentation to video frames independently. The segmented instances are then tracked by bipartite matching(二分匹配) of the corresponding queries:通过二分匹配,使得视频分割的实例可以通过query的二分匹配进行追踪
Workflow

Methods
Two stage approach
-
每一帧独立进行图像实例分割
- 图像编码器:提取特征 F
- Transformer解码器:处理编码器输出,迭代更新query embeddings(query数量 = 模型输出的最大数量instances)
- 预测head:使用最终的query embeddings来预测想要的结果(分割掩码/类标签)
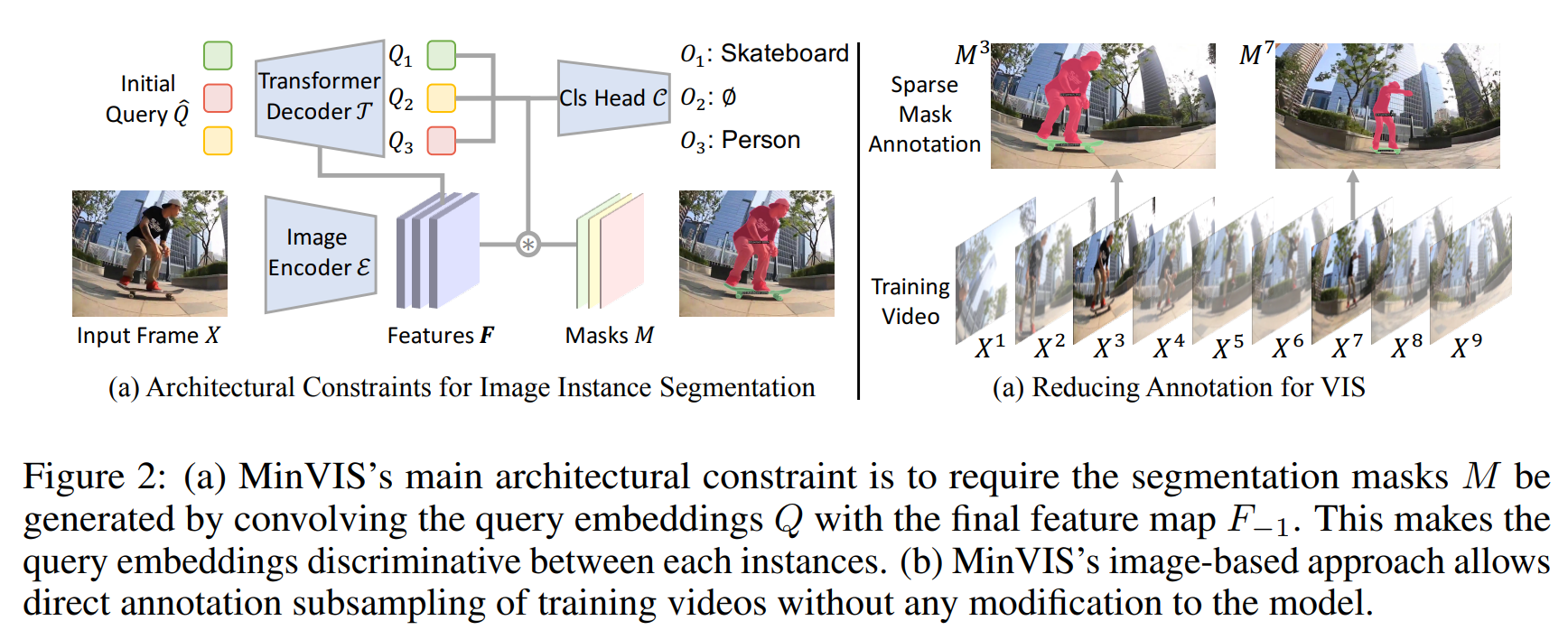

M的计算:通过内积使得query隐式地能区分不同的实例;不同帧间相同地Qi也会更相似。
-
通过匹配query,实现帧之间的实例联系(追踪)
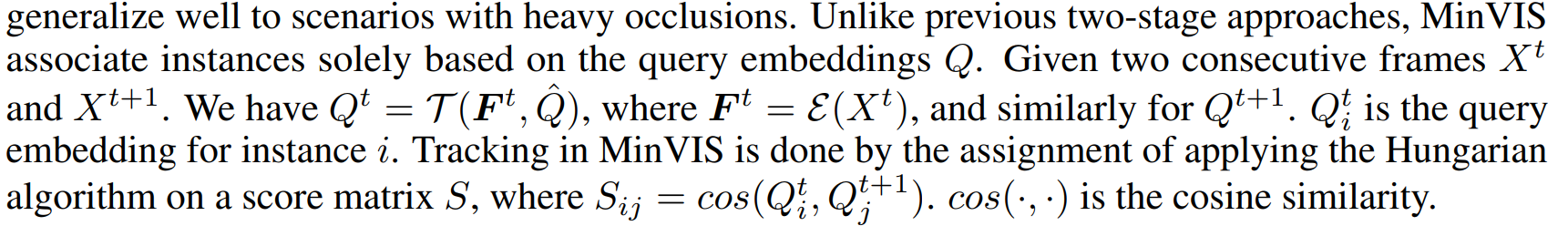
Training with Less Supervision for VIS

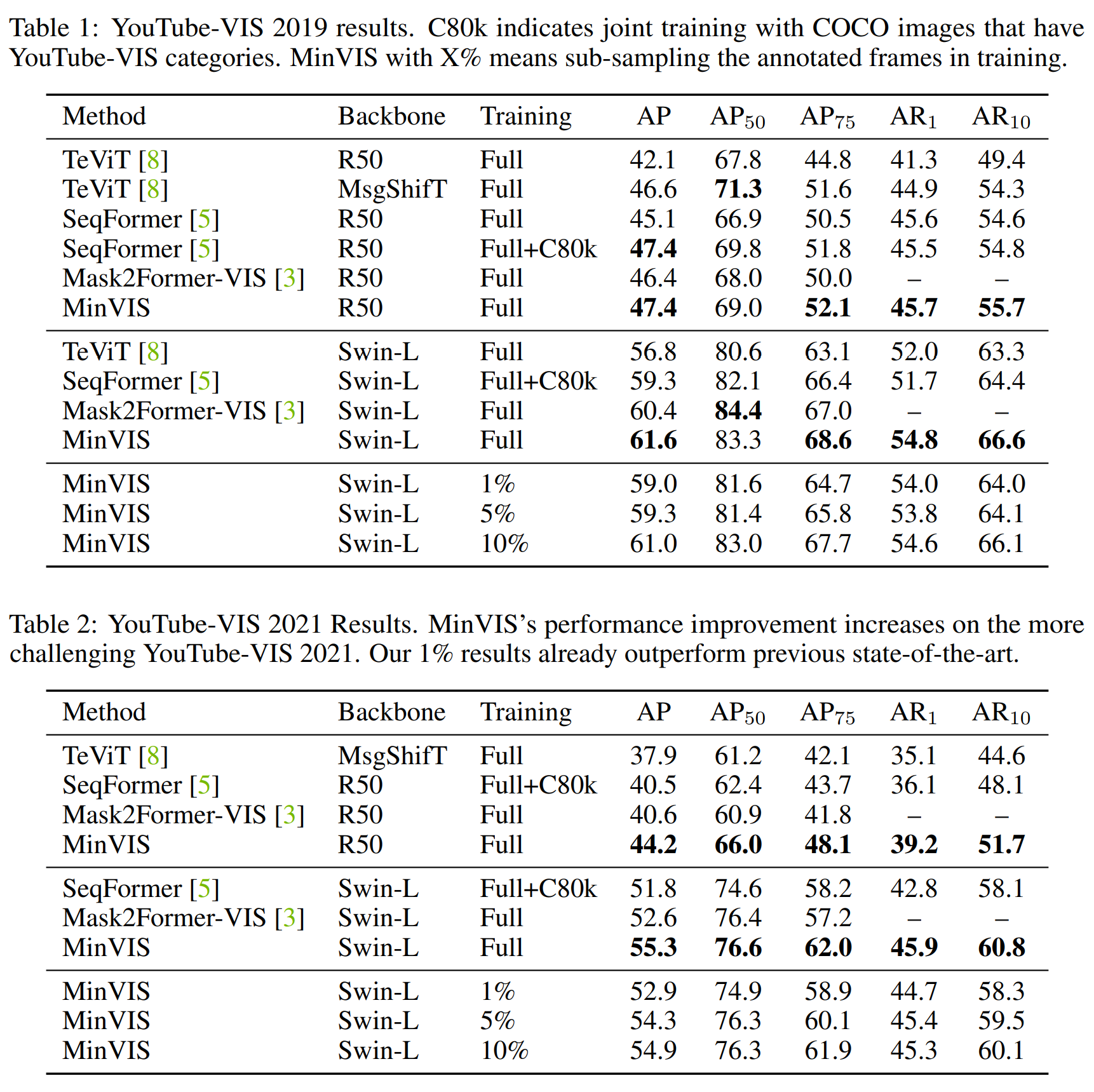
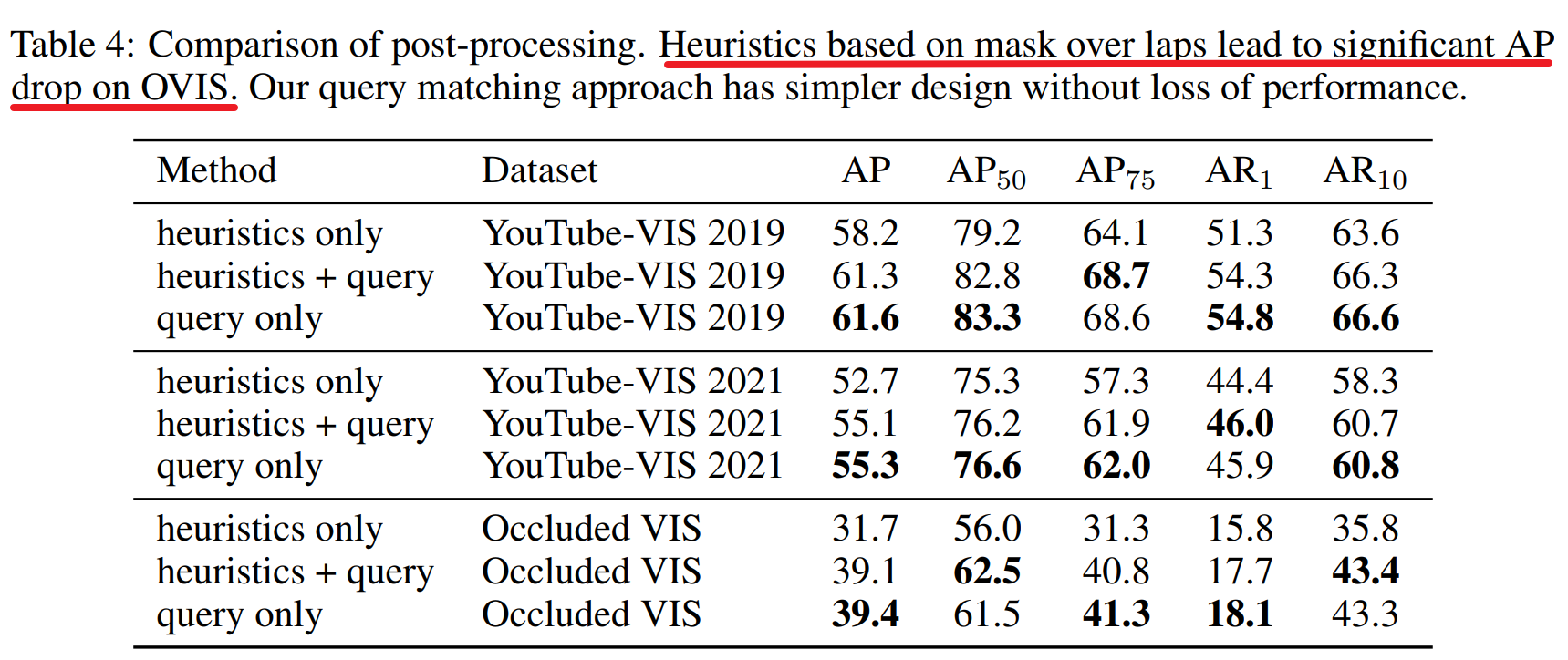
Result-show

启发和思考
- 传统的追踪:目标检测,对box进行卡尔曼滤波+匈牙利算法,有后处理;本研究 通过引入query embedding,通过将query embedding融入masks和分类头,使得query embedding获得实例的信息,进而直接对query进行追踪计算,可以加速追踪。
- 对于视频注释:提供了追踪的一种仅需要少量注释的方法,可以借鉴用于息肉视频的追踪分割注释。
代码注释
1