Title page

会议/期刊:MICCAI
年份:2022
github链接:https://github.com/WeijieMax/CPC-Trans
pdf链接: Public: https://arxiv.org/pdf/2206.11826.pdf Private
Summary
- We propose a novel method to directly achieve accurate white-light colonoscopy image classification by conducting structured cross-modal representation consistency.
- 一对多模态图像(NBI和 WL),被输入共享 Transformer 以提取分层特征表示。 随后,使用空间注意模块(SAM)来计算特定模态图像的class tokens和patch tokens之间的相似性。
- 达到了WL SOTA的性能
Workflow
Methods
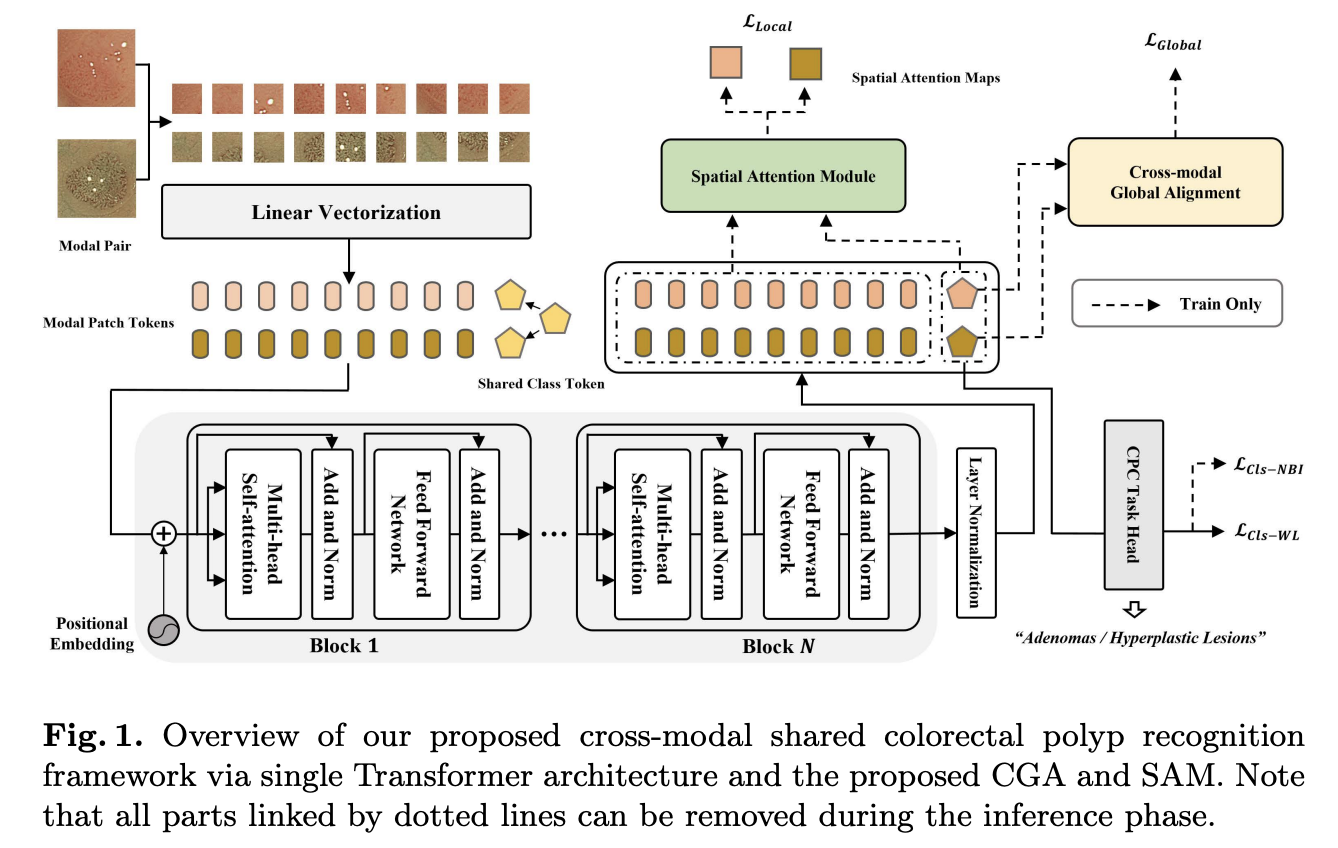
Framework OverView
-
A Transformer-based framework with cross-modal global alignment (CGA) and spatial attention module (SAM)
-
First feed a dual-modal image pair as input, the image-pair is then divided into \(P × P\) image patches
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
class CPCDataset_Multimodal(Dataset): def __init__(self, images_path1: list, images_path2: list, images_class: list, transform=None): self.images_path1 = images_path1 self.images_path2 = images_path2 self.images_class = images_class self.transform = transform def __len__(self): return len(self.images_path1) def __getitem__(self, item): img1 = Image.open(self.images_path1[item]) img2 = Image.open(self.images_path2[item]) if img1.mode != 'RGB': raise ValueError("image1: {} isn't RGB mode.".format(self.images_path1[item])) if img2.mode != 'RGB': raise ValueError("image2: {} isn't RGB mode.".format(self.images_path2[item])) label = self.images_class[item] if self.transform is not None: img1 = self.transform(img1) img2 = self.transform(img2) return img1, img2, label @staticmethod def collate_fn(batch): images1, images2, labels = tuple(zip(*batch)) images1 = torch.stack(images1, dim=0) # 一个batch的数据凭借成一个张量,shape(N, C, H, W) images2 = torch.stack(images2, dim=0) labels = torch.as_tensor(labels) return images1, images2, labels
-
After a linear projection layer, each patch is embedded into a patch token with embedded dimension \(d = \frac{3P^2}{2}\)。这里作者减少了一半的维度(为了减少计算负担)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
class PatchEmbed(nn.Module): def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None): super().__init__() img_size = (img_size, img_size) patch_size = (patch_size, patch_size) self.img_size = img_size self.patch_size = patch_size self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1]) self.num_patches = self.grid_size[0] * self.grid_size[1] self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) #线性投射 self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() def forward(self, x): B, C, H, W = x.shape assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})." x = self.proj(x).flatten(2).transpose(1, 2) x = self.norm(x) return x
-
\({X_w, X_n}\) will be successively concatenated with a shared learnable class token \(c ∈ R^d\) .
-
Positional embedding \(E ∈ R ^{(N+1)×d}\) is supplemented to \({X_w, X_n}\) and \(c\) by element-wise addition
-
Dual-modal patch tokens are separately passed through a series of shared Transformer blocks
-
During training, \(\{c_w, c_n\}\) are then fed into CGA to align dual-modal image pair’s global representation
-
SAM furthers crossmodal local alignment by comparing two modalities’ response maps between their global representation and local instance-level information.
Shared Transformer Block
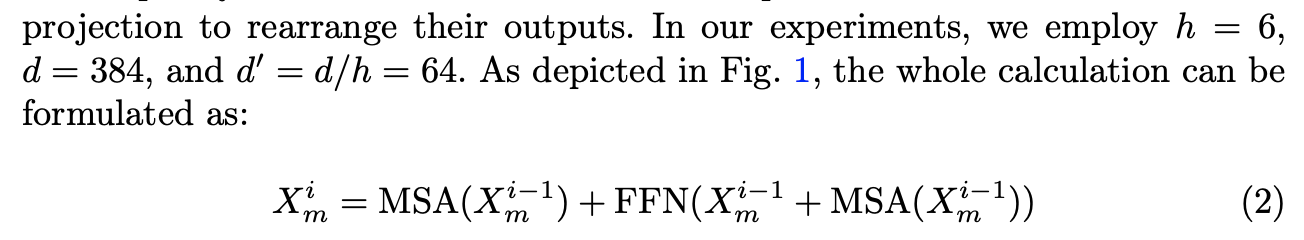
Cross-modal Global Alignment(CGA)

Spatial Attention Module
First, we obtain through SAM the globally guided affinity, i.e., the response map between each image’s global representation and local regions. Subsequently, we align two modalities’ local semantics by limiting the distance between two modalities’ response maps.

损失函数

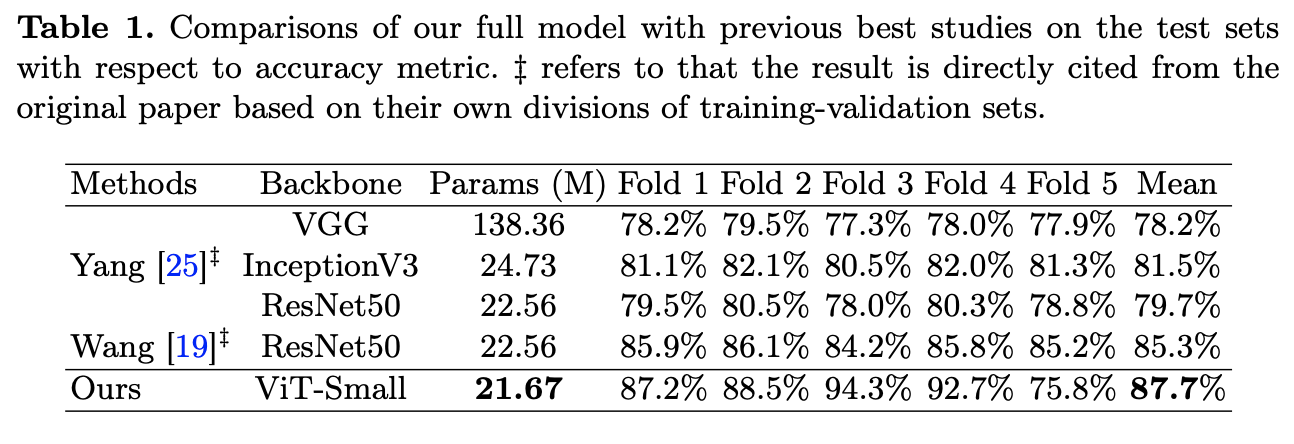
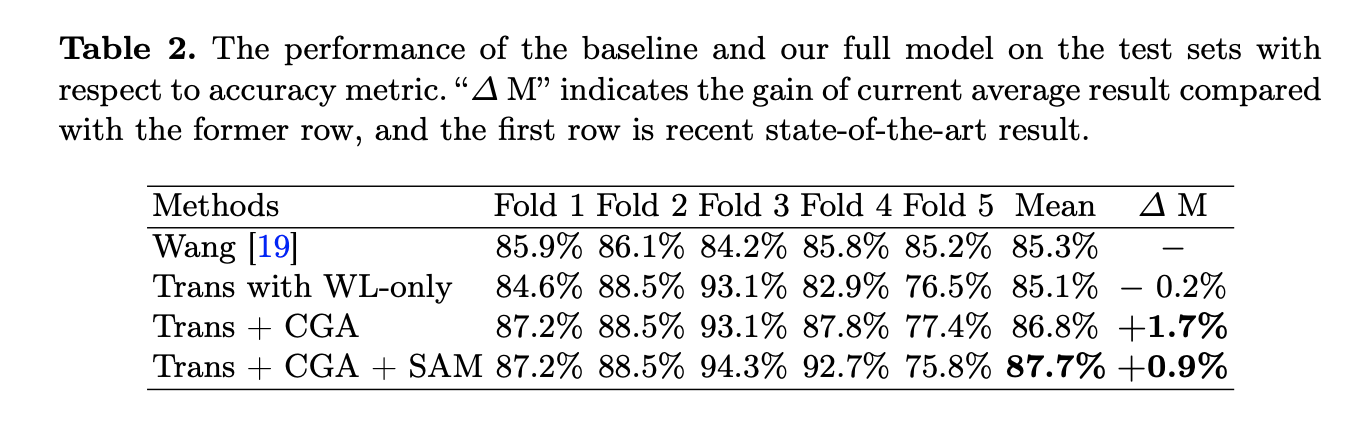
Result-show
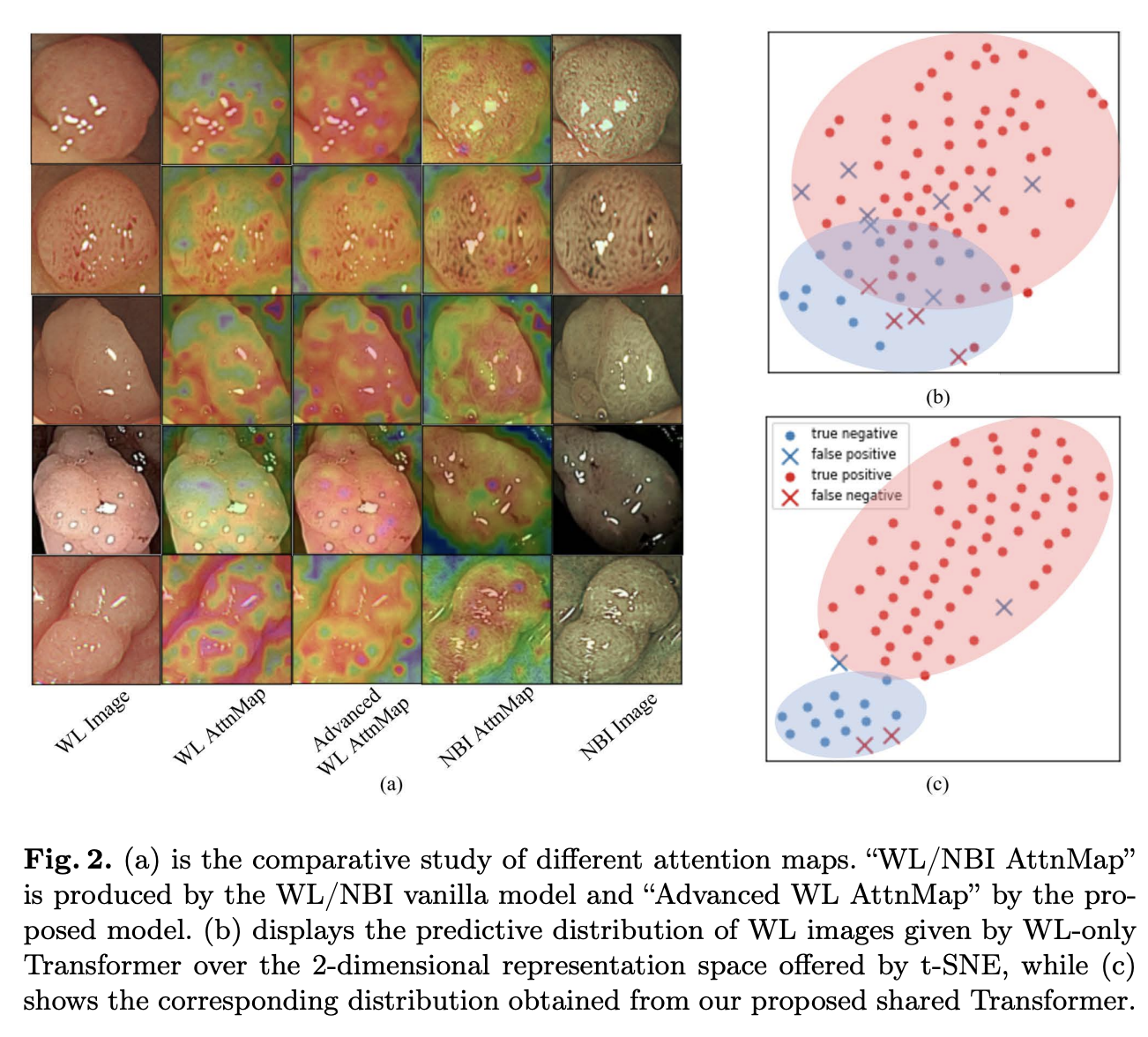
启发和思考
- 使用CPC-pair数据集的第二篇MICCAI文章
- 每个批次都序贯喂入WL与NBI图像给模型,通过共享input class token和对tokens的损失函数设计优化WL分类
- 该文章表明transformer在肠镜domian alignment领域具有很好的效果,即使使用了非常简单的共享设计,也能实现很好的效果。
- 使用半监督学习的transformer模型进行分类?
核心代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,
qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,
attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,
act_layer=None):
super(VisionTransformer, self).__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.num_tokens = 2 if distilled else 1
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
act_layer = act_layer or nn.GELU
self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
self.pos_drop = nn.Dropout(p=drop_ratio)
dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)]
self.blocks = nn.Sequential(*[
Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],
norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)
])
self.norm = norm_layer(embed_dim)
self.SAM = nn.MultiheadAttention(embed_dim, num_heads, dropout=0.1)
if representation_size and not distilled:
self.has_logits = True
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
("fc", nn.Linear(embed_dim, representation_size)),
("act", nn.Tanh())
]))
else:
self.has_logits = False
self.pre_logits = nn.Identity()
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.head_dist = None
if distilled:
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()
nn.init.trunc_normal_(self.pos_embed, std=0.02)
if self.dist_token is not None:
nn.init.trunc_normal_(self.dist_token, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
self.apply(_init_vit_weights)
def forward_features(self, x1, x2):
x1 = self.patch_embed(x1)
x2 = self.patch_embed(x2)
cls_token = self.cls_token.expand(x1.shape[0], -1, -1)
x1 = torch.cat((cls_token, x1), dim=1)
x2 = torch.cat((cls_token, x2), dim=1)
x1 = self.pos_drop(x1 + self.pos_embed)
x1 = self.blocks(x1)
x1 = self.norm(x1)
x2 = self.pos_drop(x2 + self.pos_embed)
x2 = self.blocks(x2)
x2 = self.norm(x2)
return self.pre_logits(x1[:, 0]), self.pre_logits(x1[:, 1:]), self.pre_logits(x2[:, 0]), self.pre_logits(x2[:, 1:])
def forward(self, x1, x2):
cls_token1, patch_embed1, cls_token2, patch_embed2 = self.forward_features(x1, x2)
if self.head_dist is not None:
x1, x1_dist = self.head(x1[0]), self.head_dist(x1[1])
x2, x2_dist = self.head(x2[0]), self.head_dist(x2[1])
if self.training and not torch.jit.is_scripting():
return x1, x1_dist, x2, x2_dist
else:
return (x1 + x1_dist) / 2, (x2 + x2_dist) / 2
else:
# (n1,b,c) (n2,b,c) (n2,b,c) -> out:(n1,b,c) attn_map:(b,n1,n2)
_, attn_output_weights11 = self.SAM(cls_token1.unsqueeze(0), patch_embed1.transpose(1,0), patch_embed1.transpose(1,0))
_, attn_output_weights22 = self.SAM(cls_token2.unsqueeze(0), patch_embed2.transpose(1,0), patch_embed2.transpose(1,0))
pred1 = self.head(cls_token1)
pred2 = self.head(cls_token2)
return pred1, pred2, cls_token1, cls_token2, attn_output_weights11.squeeze(), attn_output_weights22.squeeze()