Title page

会议:Accepted at Medical Image Analysis
年份:2022
pdf链接: Public: http://arxiv.org/abs/2108.02476 Private
Summary
- 视网膜分割模型(edge enhancement (DE-DCGCN-EE)) 基于UNet改造
- edge detection-based dual encoder 边缘检测双编码器
- dynamic-channel graph convolutional network
- edge enhancement block
Workflow

Methods
OverView
-
主要包含两个子网络:student network和teacher network,使用的是Se-ResNeXt50模型
-
Input预处理:add different perturbations (e.g. Gaussian noise)
-
独立输入两个结构相同的网络,产生Prediction(knee cartilage defect severity probabilities)和对应的异常attention mask
- Attention mask:使用了 log-sum-exp(LSE) pooling, 而不是 global average pooling(GAP)
-
The student model is constrained by both the supervised loss (classification loss and attention loss) and unsupervised loss (classification consistency loss and attention consistency loss).
- classification loss: cross-entropy classification loss
- attention loss
- consistency loss: MSE
-
The teacher model is updated through the exponential moving average (EMA) strategy.
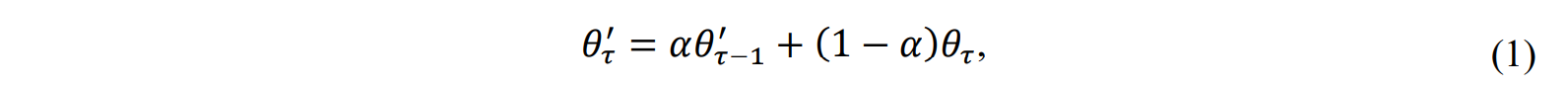
Attention Loss for cartilage region localization
-
受CAM策略(Li et al. 2018; Ouyang, Huo, et al. 2020; Ouyang, Karanam, et al. 2020) 启发,该文章生成了attention mask,表明模型对局部缺陷区域的诊断优先度
-
首先使用内部标注工具进行了股骨软骨区域分割,获得mask $C_i$ 作为attention mask的labels,该标注工具的dice值为0.781±0.047,作者认为已经可以用于软骨区域定位任务
-
Attention Loss的计算:$L_{att}$ 是 学生网络输出 $f_{\theta}(x_i)$与$C_i$的MSE,$L_{con}$是额外的边界限制损失函数

Dual Consistency Loss Functions
除了mean-teacher模型中的分类损失函数外
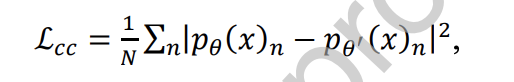
还提出了注意力一致性Loss
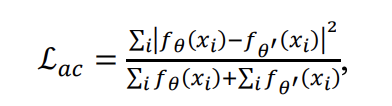
Total Loss function
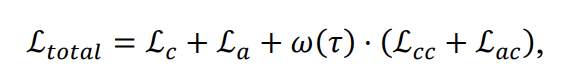
注意:作者发现网络的无监督部分收敛不佳,认为可能是由于教师模型在训练开始时not in a good condition。为此,他们使用了 $\omega(\tau)$作为warm-up函数,来两证dual consistency loss的权重因子。

Aggregation Network for Subject-Level Diagnosis
改良后的mean-teacher模型可以用于slice-level水平的分类;作者认为单纯的集成方法(the possible classification errors from the slice-level model can greatly influence the subject-level estimation),因此引入了GRU在构建聚合集成网络
- A 512 × k(the number of slices) feature sequence is generated after feature extraction from the student model
- To handle the unlabeled data, we also conduct the mean teacher mechanism for the training of the aggregation network, and preserve the conventional individual consistency mechanism
Result-show

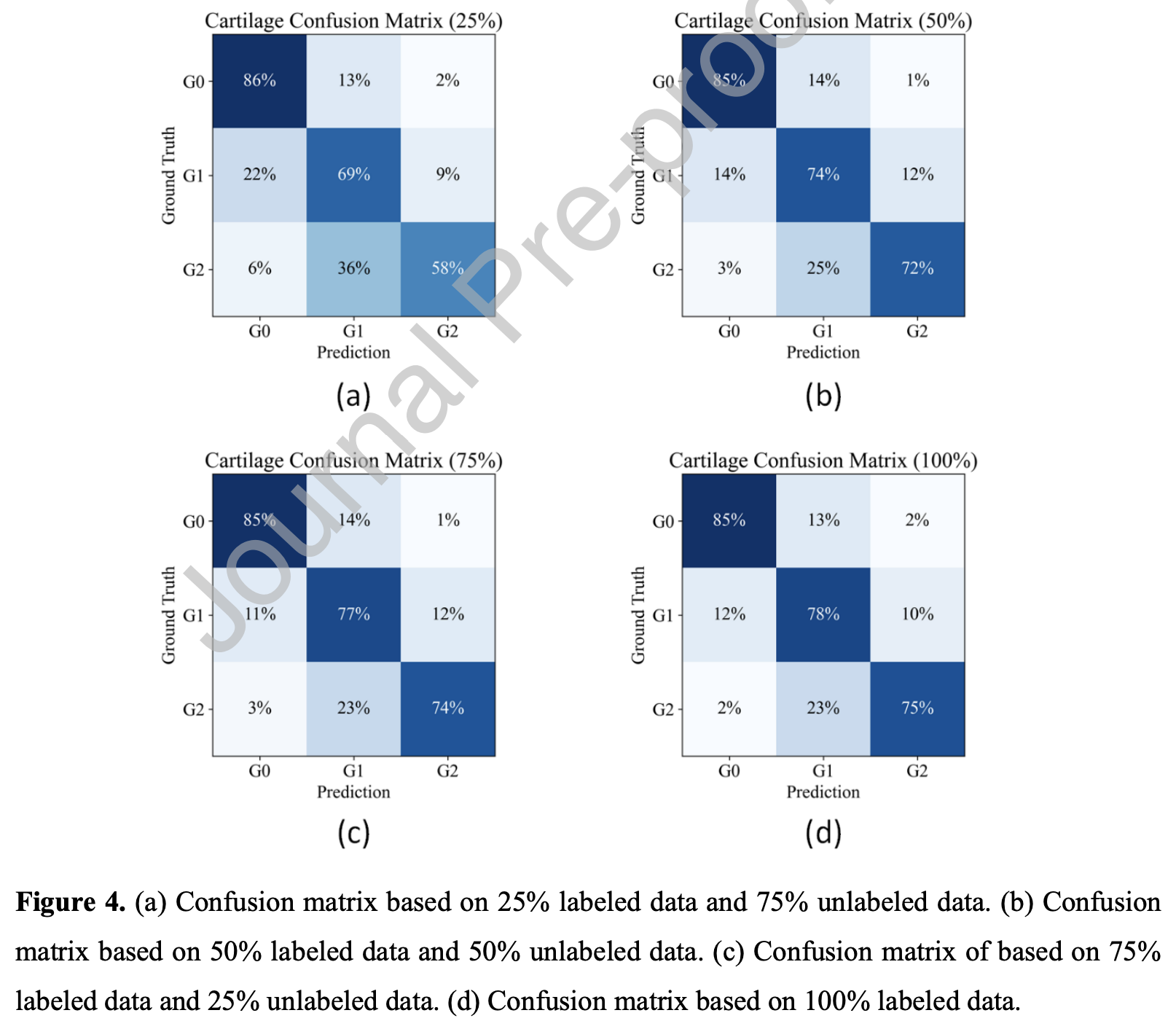
Ablation study
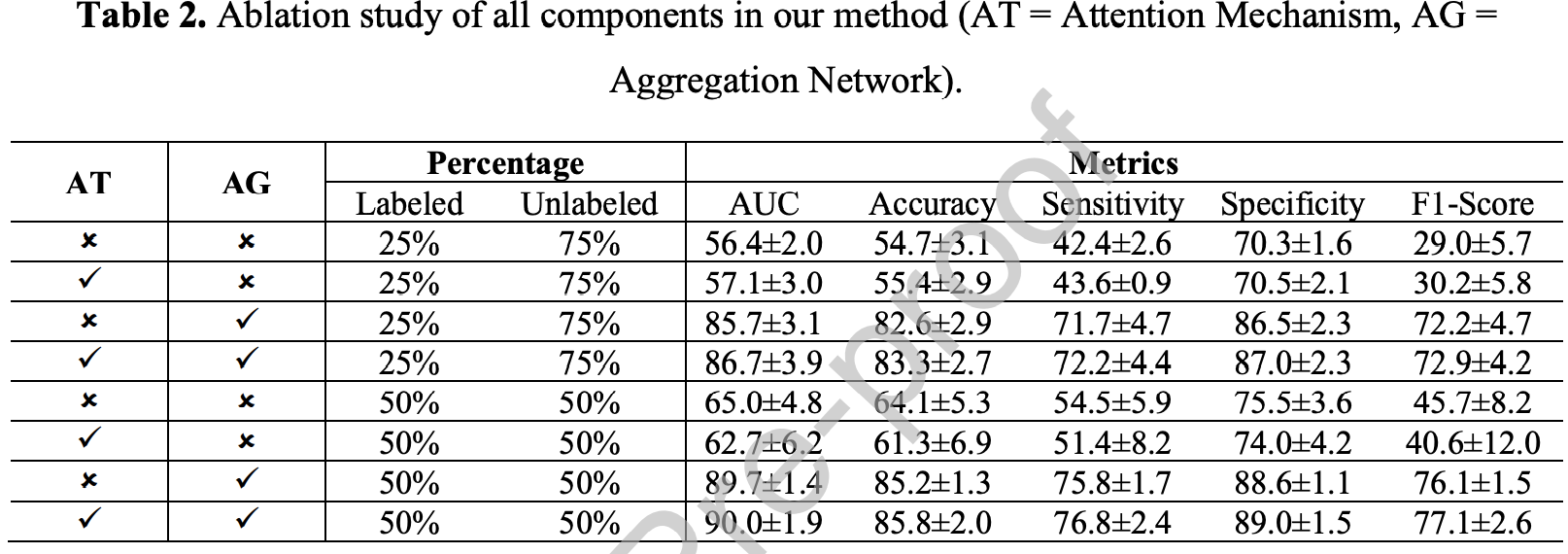
可以看到AG效果显著,AT效果一般,50%-50%时不如不加,但AT+AG均达到了最好的效果
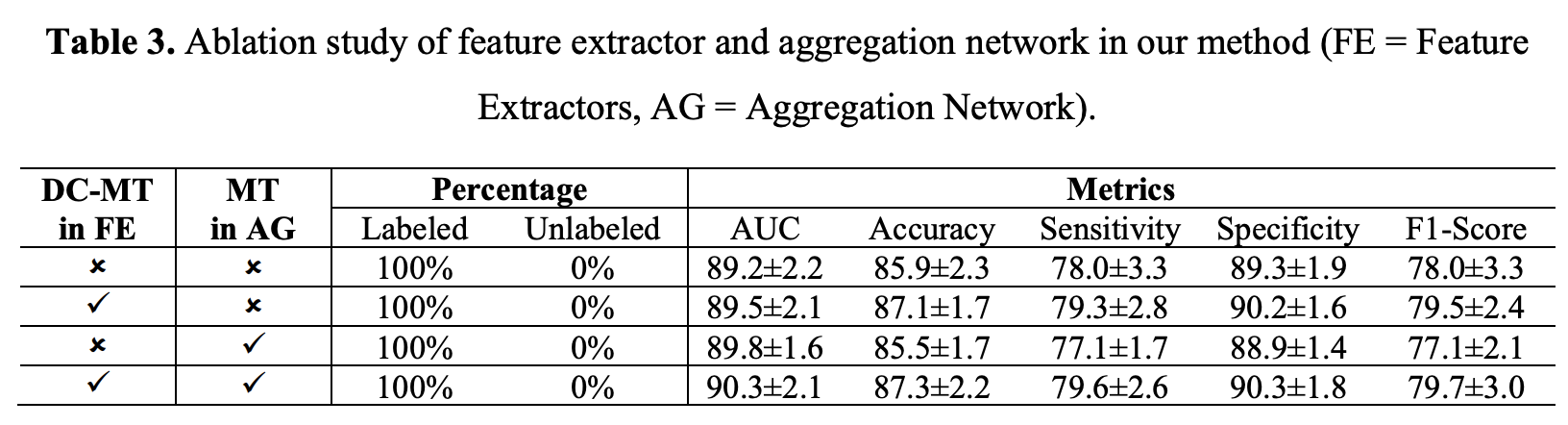
- There are two types of feature extractor and aggregation network. For feature extractors, the two types are DC-MT and single 2D slice classification network, the backbone of these two feature extractors is SE-ResNeXt50. There are also two types of aggregation network, their main difference is whether the mean teacher strategy is contained or not.
- 单独使用MT in AG效果不佳,单独使用DC-MT效果显著,两者一起用效果最好
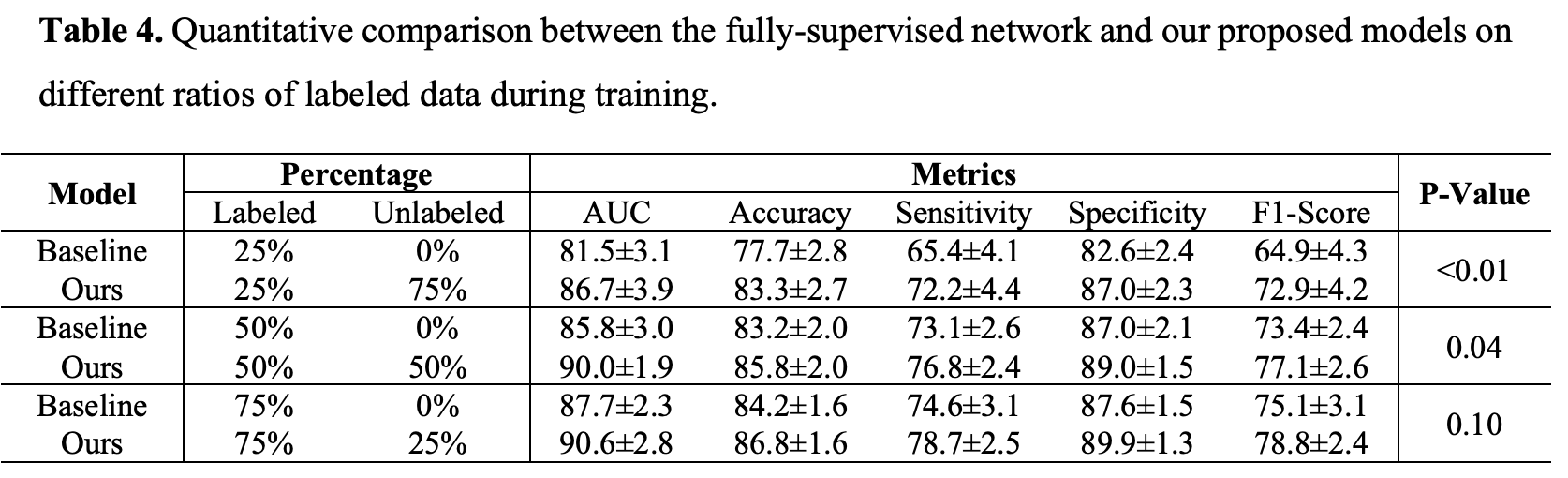
定量比较
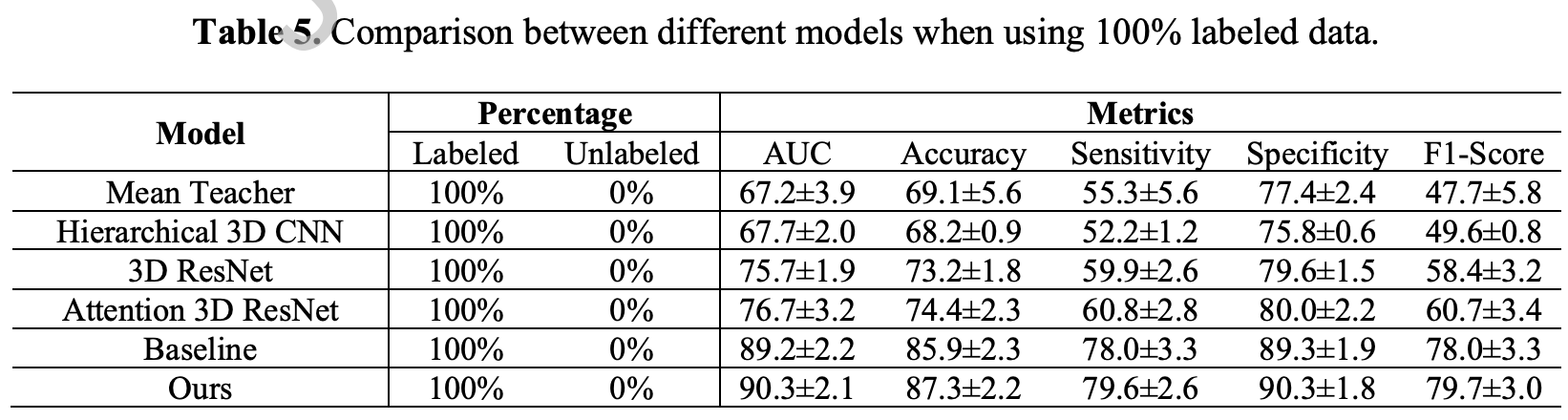
异常定位能力
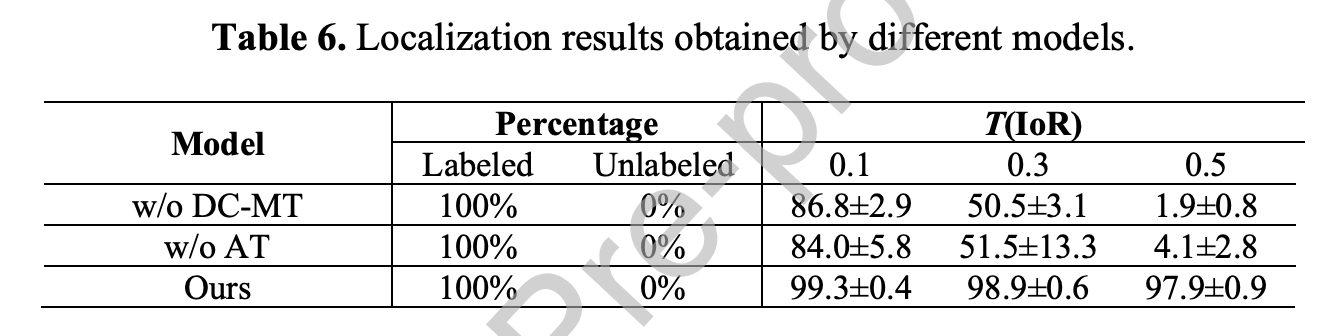
“w/o DC-MT” refers to the model without the DC-MT mechanism and the attention loss, that it merely contains the conventional SE-ResNeXt50. Meanwhile, “w/o AT” means that we add the conventional MT framework but without the attention loss to make the network focus on the cartilage segmentation mask.
定性比较
略
启发和思考
- 一个改良的two stage模型,slice-level的定位,subject-level的分类,与肠镜系统类似
- 定位使用了半监督学习+多任务学习,引入了attention guided mask;分类使用了BiGRU+残差思想,对k张slice进行统一推理分类
- 消融实验做得较为充分,可以看出
- 多slice-level聚合(AG)的效果非常显著 → 将BiGRU改换成Attention?
- DC-MT在特征提取方面效果显著
- AG网络中使用MC效果一般
核心代码
train.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
def train(visualizer, train_loader, model, optimizer, epoch, config, cls_criterion):
StudentModel, TeacherModel = model
losses = AverageMeter()
cls_losses = AverageMeter()
attmse_losses = AverageMeter()
attbound_losses = AverageMeter()
consiscls_losses = AverageMeter()
consisatt_losses = AverageMeter()
batch_time = AverageMeter()
cls_ACCs = AverageMeter()
cls_AUCs = AverageMeter()
cls_F1s = AverageMeter()
StudentModel.train()
TeacherModel.train()
end = time.time()
for i, (input, ema_input, label, _, _) in enumerate(train_loader):
with torch.autograd.set_detect_anomaly(True):
image1, masks1 = input
image2, _ = ema_input
im_h = image1.size(2)
im_w = image1.size(3)
bs = image1.size(0)
label_bs = config['label_bs']
visualizer.reset()
visual_ret = OrderedDict()
errors_ret = OrderedDict()
image1 = image1.cuda()
masks1 = masks1.cuda()
image2 = image2.cuda()
masks1 = masks1.unsqueeze(1)
label = label.cuda()
visual_ret['input'] = image1
masks_vis = visual_masks(masks1, im_h, im_w)
visual_ret['mask'] = masks_vis
output_s, cam_refined_s, _ = StudentModel(image1)
output_t, cam_refined_t, _ = TeacherModel(image2)
class_idx = label.cpu().long().numpy()
for index, idx in enumerate(class_idx):
tmp1 = cam_refined_s[index, idx, :, :].unsqueeze(0).unsqueeze(1)
tmp2 = cam_refined_t[index, idx, :, :].unsqueeze(0).unsqueeze(1)
if index == 0:
cam_refined_class_s = tmp1
cam_refined_class_t = tmp2
else:
cam_refined_class_s = torch.cat((cam_refined_class_s, tmp1), dim=0)
cam_refined_class_t = torch.cat((cam_refined_class_t, tmp2), dim=0)
cam_refined_s = cam_refined_class_s
cam_refined_t = cam_refined_class_t
### Classification
probe = torch.softmax(output_s, dim=1)
cls_loss = cls_criterion(torch.log(probe[:label_bs]), label[:label_bs])
### Attention
## MSE loss
mask_loss = mask_mse_loss_func(masks1[:label_bs], cam_refined_s[:label_bs])
## Bound loss
bound_loss = torch.tensor(1) - torch.min(masks1[:label_bs], cam_refined_s[:label_bs]).sum((2, 3)) / torch.clamp(cam_refined_s[:label_bs].sum((2, 3)), min=1e-5)
bound_loss = bound_loss.sum() / bs
gcams_vis = visual_masks(cam_refined_s.float(), im_h, im_w)
visual_ret['attention'] = gcams_vis
### Attention Consistency
consistency_weight_att = get_current_consistency_att_weight(epoch, config)
consistency_loss_att = consistency_weight_att * consistency_criterion_att(cam_refined_s[label_bs:],
cam_refined_t[label_bs:])
### Classification Consistency
consistency_weight_cls = get_current_consistency_cls_weight(epoch, config)
consistency_loss_cls = consistency_weight_cls * consistency_criterion_cls(output_s,
output_t)
## Ours
if epoch < 20:
total_loss = loss_cls * cls_loss + loss_masks * mask_loss + loss_bound * bound_loss
else:
total_loss = loss_cls * cls_loss + loss_masks * mask_loss + loss_bound * bound_loss + consistency_loss_cls + consistency_loss_att
errors_ret['ClsLoss'] = float(cls_loss)
errors_ret['AttMseLoss'] = float(mask_loss)
errors_ret['AttBoundLoss'] = float(bound_loss)
errors_ret['ConsisClsLoss'] = float(consistency_loss_cls)
errors_ret['ConsisAttLoss'] = float(consistency_loss_att)
errors_ret['Loss'] = float(total_loss)
losses.update(total_loss.item(), bs)
cls_losses.update(cls_loss.item(), bs)
attmse_losses.update(mask_loss.item(), bs)
attbound_losses.update(bound_loss.item(), bs)
consiscls_losses.update(consistency_loss_cls.item(), bs)
consisatt_losses.update(consistency_loss_att.item(), bs)
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
update_ema_variables(StudentModel, TeacherModel, config['ema_decay'], epoch)
m_acc, _ = recall(probe.cpu().detach().numpy(), label.cpu().detach().numpy(), config)
cls_ACCs.update(m_acc, bs)
m_auc, _ = calculate_auc(probe.cpu().detach().numpy(), label.cpu().detach().numpy(), config)
cls_AUCs.update(m_auc, bs)
m_f1, _ = calculate_f1(probe.cpu().detach().numpy(), label.cpu().detach().numpy(), config)
cls_F1s.update(m_f1, bs)
batch_time.update(time.time() - end)
end = time.time()
if i % config['print_freq'] == 0:
logging.info('Epoch: [{}][{}/{}]\t'
'ConsistencyWeightAtt: {:.4f} '
'Loss: {loss.val:.4f} ({loss.avg:.4f}) '
'ClsLoss: {cls_loss.val:.4f} ({cls_loss.avg:.4f}) '
'AttMseloss: {attmse_loss.val:.4f} ({attmse_loss.avg:.4f}) '
'AttBndLoss: {attbnd_loss.val:.4f} ({attbnd_loss.avg:.4f}) '
'ConsisClsLoss: {concls_loss.val:.4f} ({concls_loss.avg:.4f}) '
'ConsisAttLoss: {conatt_loss.val:.4f} ({conatt_loss.avg:.4f}) '
'ClsF1: {cls_f1.val:.4f} ({cls_f1.avg:.4f}) '.format(
epoch, i, len(train_loader), consistency_weight_att, loss=losses, cls_loss=cls_losses, attmse_loss=attmse_losses,
attbnd_loss=attbound_losses, concls_loss=consiscls_losses, conatt_loss=consisatt_losses, cls_f1=cls_F1s))
if config['display_id'] > 0:
visualizer.plot_current_losses(epoch, float(i) / float(len(train_loader)), errors_ret)
if i % config['display_freq'] == 0:
visualizer.display_current_results(visual_ret, class_idx[0], epoch, save_result=False)
Attention cams:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
def refine_cams(cam_original, image_shape, using_sigmoid=True):
if image_shape[0] != cam_original.size(2) or image_shape[1] != cam_original.size(3):
cam_original = F.interpolate(
cam_original, image_shape, mode="bilinear", align_corners=True
)
B, C, H, W = cam_original.size()
cams = []
for idx in range(C):
cam = cam_original[:, idx, :, :]
cam = cam.view(B, -1)
cam_min = cam.min(dim=1, keepdim=True)[0]
cam_max = cam.max(dim=1, keepdim=True)[0]
norm = cam_max - cam_min
norm[norm == 0] = 1e-5
cam = (cam - cam_min) / norm
cam = cam.view(B, H, W).unsqueeze(1)
cams.append(cam)
cams = torch.cat(cams, dim=1)
if using_sigmoid:
cams = torch.sigmoid(cam_w*(cams - cam_sigma))
return
class SENet(nn.Module):
def __init__(self, block, layers, groups, reduction, dropout_p=0.2,
inplanes=128, input_3x3=True, downsample_kernel_size=3,
downsample_padding=1, num_classes=1000):
super(SENet, self).__init__()
self.inplanes = inplanes
if input_3x3:
layer0_modules = [
('conv1', nn.Conv2d(3, 64, 3, stride=2, padding=1,
bias=False)),
('bn1', nn.BatchNorm2d(64)),
('relu1', nn.ReLU(inplace=True)),
('conv2', nn.Conv2d(64, 64, 3, stride=1, padding=1,
bias=False)),
('bn2', nn.BatchNorm2d(64)),
('relu2', nn.ReLU(inplace=True)),
('conv3', nn.Conv2d(64, inplanes, 3, stride=1, padding=1,
bias=False)),
('bn3', nn.BatchNorm2d(inplanes)),
('relu3', nn.ReLU(inplace=True)),
]
else:
layer0_modules = [
('conv1', nn.Conv2d(3, inplanes, kernel_size=7, stride=2,
padding=3, bias=False)),
('bn1', nn.BatchNorm2d(inplanes)),
('relu1', nn.ReLU(inplace=True)),
]
# To preserve compatibility with Caffe weights `ceil_mode=True`
# is used instead of `padding=1`.
layer0_modules.append(('pool', nn.MaxPool2d(3, stride=2,
ceil_mode=True)))
self.conv_2_img = nn.Conv2d(inplanes, 3, kernel_size=1, stride=1, padding=0, bias=False)
self.layer0 = nn.Sequential(OrderedDict(layer0_modules))
self.layer1 = self._make_layer(
block,
planes=64,
blocks=layers[0],
groups=groups,
reduction=reduction,
downsample_kernel_size=1,
downsample_padding=0
)
self.layer2 = self._make_layer(
block,
planes=128,
blocks=layers[1],
stride=2,
groups=groups,
reduction=reduction,
downsample_kernel_size=downsample_kernel_size,
downsample_padding=downsample_padding
)
self.layer3 = self._make_layer(
block,
planes=256,
blocks=layers[2],
stride=2,
groups=groups,
reduction=reduction,
downsample_kernel_size=downsample_kernel_size,
downsample_padding=downsample_padding
)
self.layer4 = self._make_layer(
block,
planes=512,
blocks=layers[3],
stride=1,
groups=groups,
reduction=reduction,
downsample_kernel_size=downsample_kernel_size,
downsample_padding=downsample_padding
)
num_feautures = 512 * block.expansion
num_inner = num_feautures // 4
self.fa_layer = FAModule(num_feautures, num_inner)
self.cls_head = nn.Sequential(
conv3x3(num_feautures + num_inner, 512),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Dropout2d(0.1)
)
self.dropout = nn.Dropout(dropout_p) if dropout_p is not None else None
self.mu = nn.Linear(512, num_classes) # 添加了分类头
def _make_layer(self, block, planes, blocks, groups, reduction, stride=1,
downsample_kernel_size=1, downsample_padding=0):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=downsample_kernel_size, stride=stride,
padding=downsample_padding, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, groups, reduction, stride,
downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, groups, reduction))
return nn.Sequential(*layers)
def features(self, x):
x = self.layer0(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x
def forward(self, x):
w = x.shape[2]
h = x.shape[3]
x = self.features(x)
x_fa, fab = self.fa_layer(x)
x_cat = self.cls_head(torch.cat((x, x_fa), dim=1))
out_pool = LSE_Pooling(x_cat)
out = self.mu(out_pool)
gcams = F.relu(F.conv2d(x_cat, self.mu.weight.detach().unsqueeze(2).unsqueeze(3), bias=None, stride=1, padding=0), inplace=True)
gcams_refined = refine_cams(gcams, (w, h), using_sigmoid=True)
return out, gcams_refined, out_pool