Title page

会议:Accepted at MICCAI-21
年份:2021
github链接:https://github.com/dashishi/LDPolypVideo-Benchmark
pdf链接:
Summary
-
提出了一个新的Benchmark息肉数据集,contains 160 colonoscopy videos and 40,266 frames in total with polyp annotations
- 基于目标追踪,设计了一个自动化的标注工具
- The average drops of Recall and Precision of four SOTA approaches on this dataset are 26% and 15%, respectively
Workflow
无
Methods
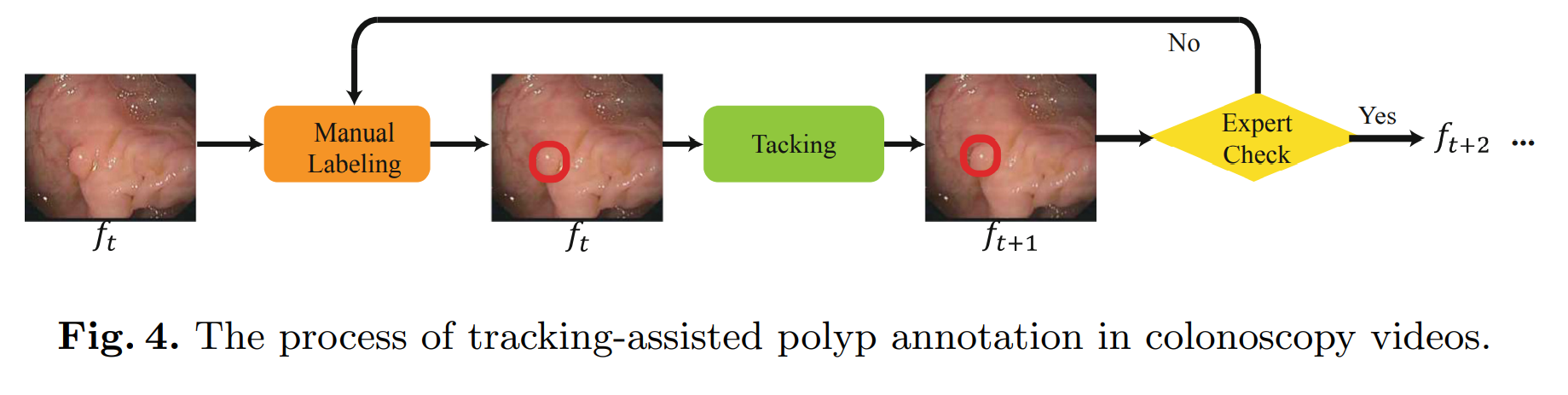
Tracking-Assisted Annotation Tool
- Considering efficiency and accuracy, we choose the Kernelized correlation filtering method
- 具体标注方法:两名专家,第一名独立标注息肉起始帧,机器自动追踪后修改;第二名独立核对
- For each video, we ask an expert to label a polyp when it first appears.
- The tracker automatically predicts its position in the next frame.
- If the tracking result is not satisfied, manual annotation is performed on this new frame and tracking continues.
- After a round of labeling for the entire video, we ask another expert to verify the annotations and make modifications if necessary.
- 标注效率:For the 894 frames in these two videos, the polyps in 681 frames can be automatically annotated and only 80 frames require manual re-annotation.
Result-show
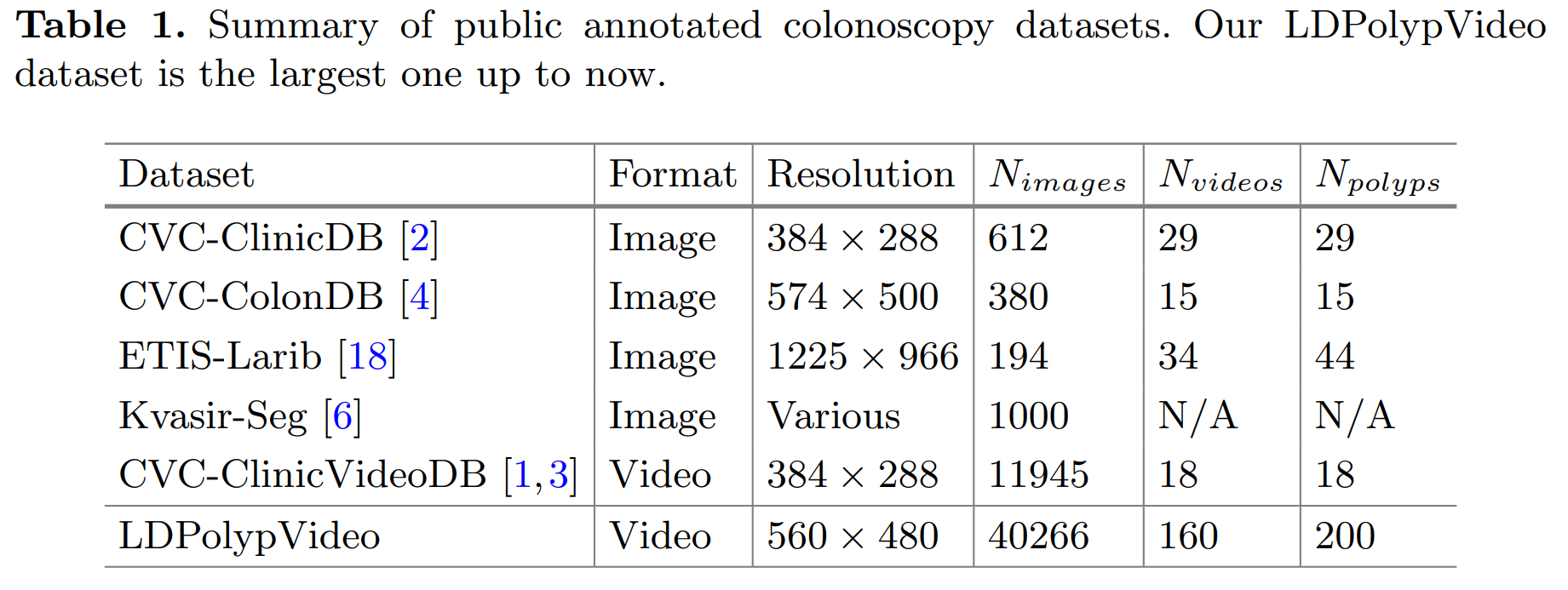
1. 数据集概览及与过去其他数据集比较
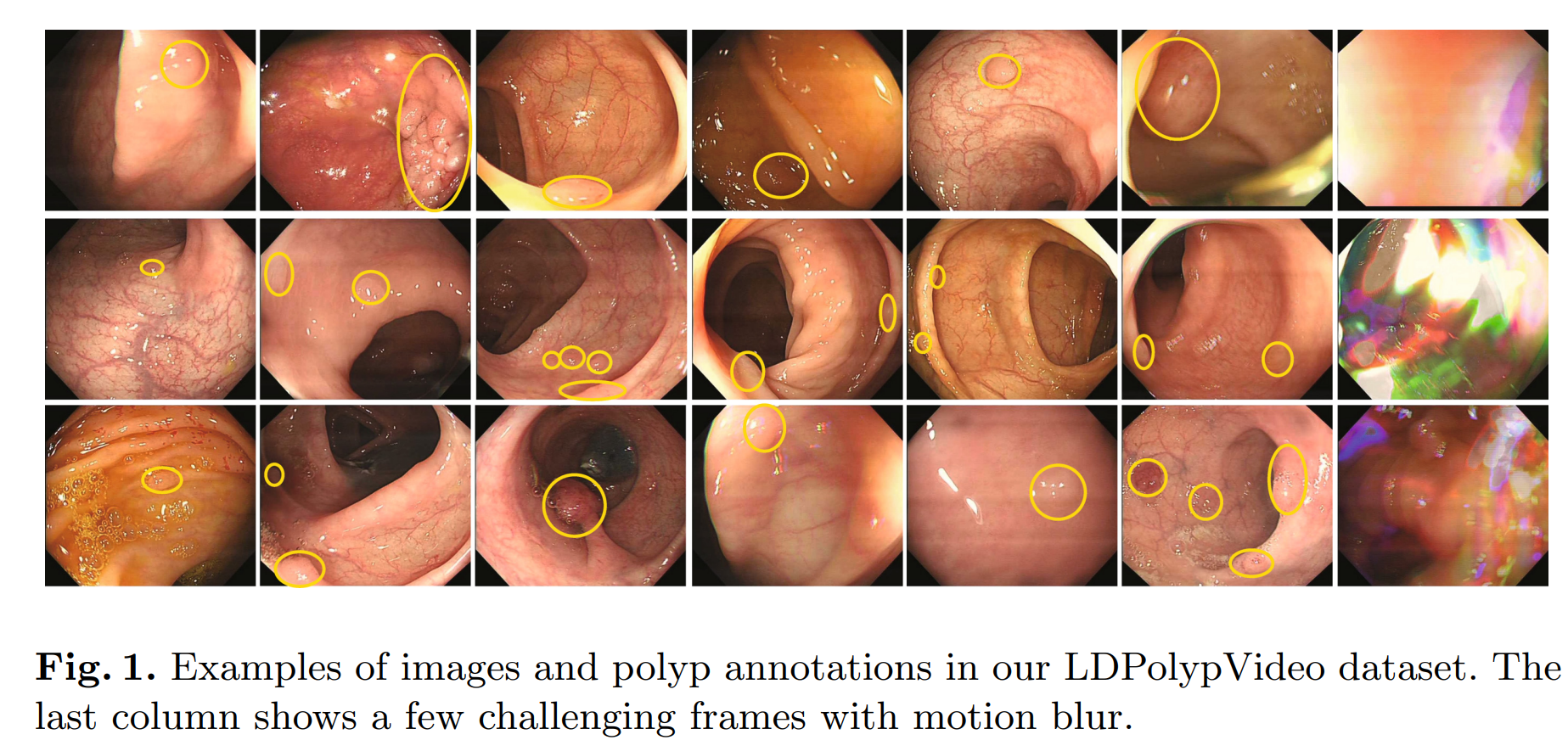
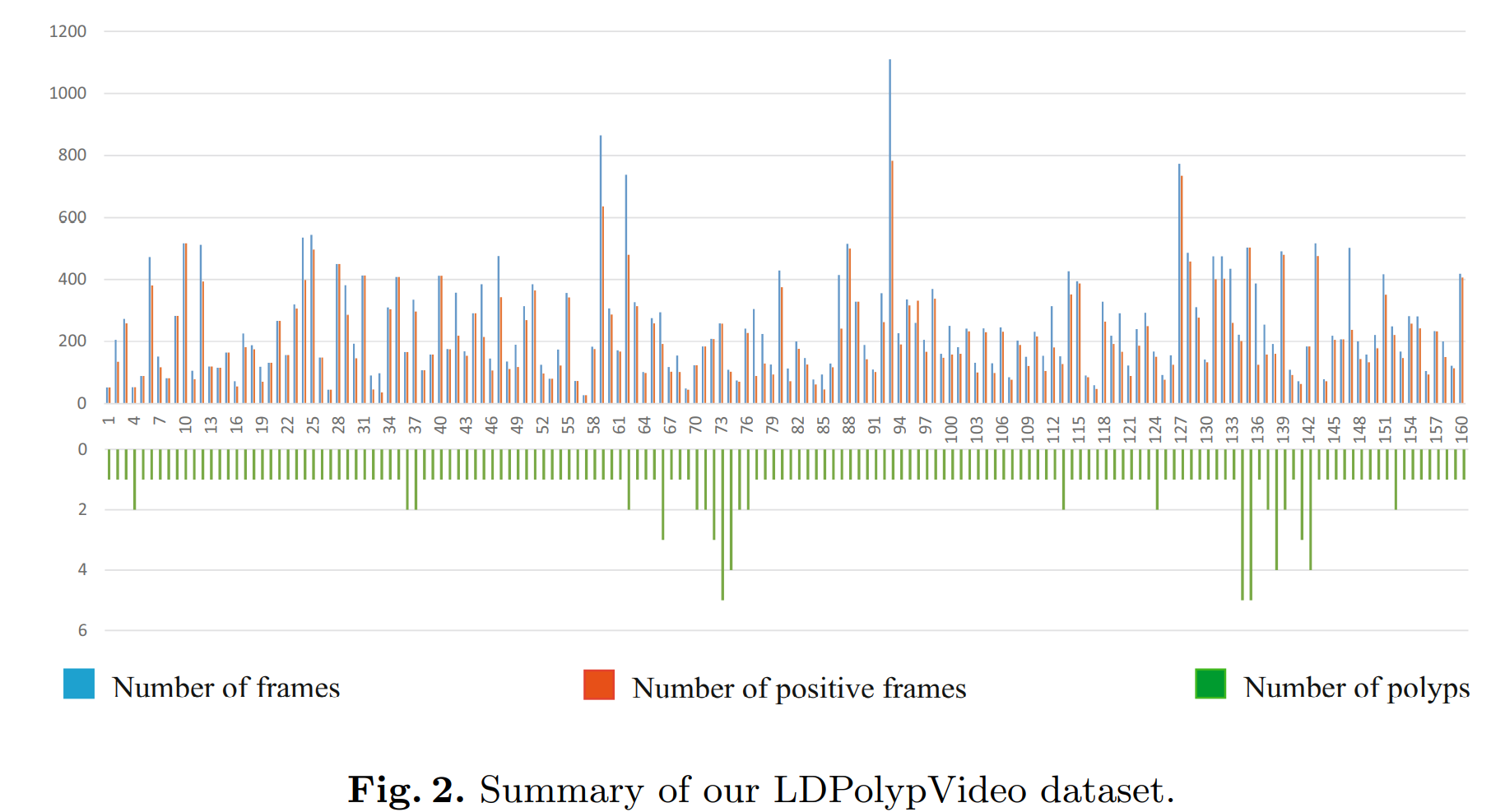
2. 数据集详情

- 单中心
- 所有元数据被移除
- An experienced clinician selects video clips that contain polyps
- 分辨率:560 × 480
- 标注类型:bbox
- 肠镜类型:Olympu-290
- 已标注:160个视频,共40266帧,每个视频中至少含有一颗息肉
- 33884帧含有至少1颗息肉
- 共有200颗息肉(CVC-ClinicVideoDB的11倍)
- 未标注:we also provide 103 videos, including 861,400 frames without full annotations —— 可用于半监督或无监督学习
- 新增加的场景:motion blur caused by camera movement, colon folds 结肠皱襞, and intestinal peristalsis 肠道蠕动; multiple polyps in a single frame(22个视频中含有多颗息肉)
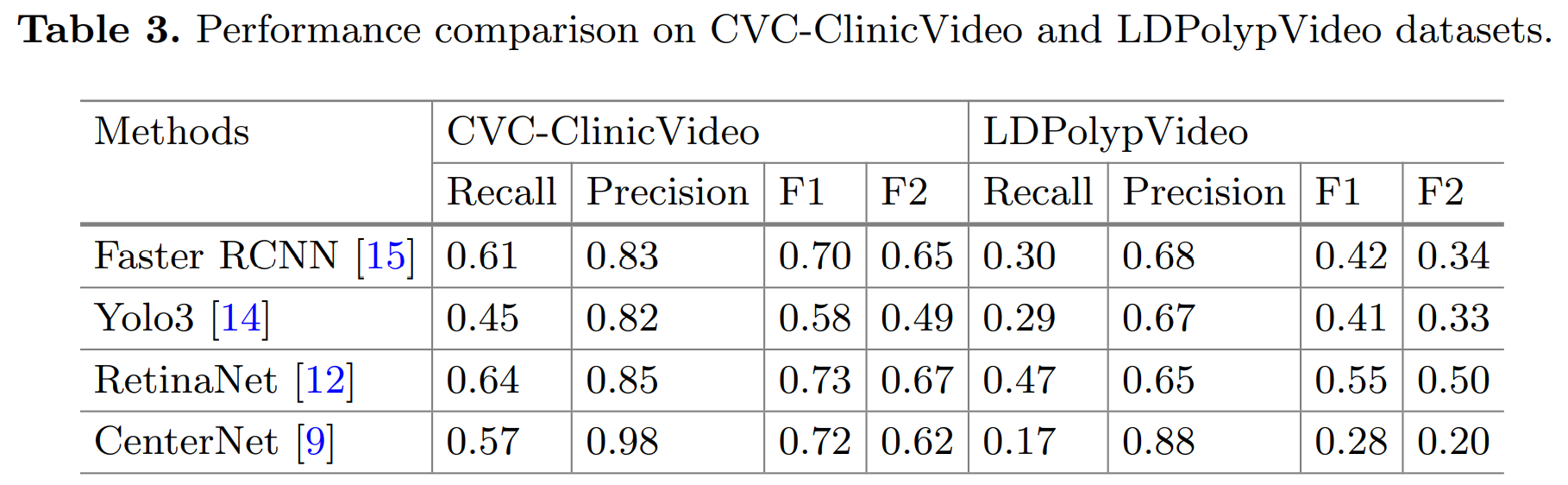
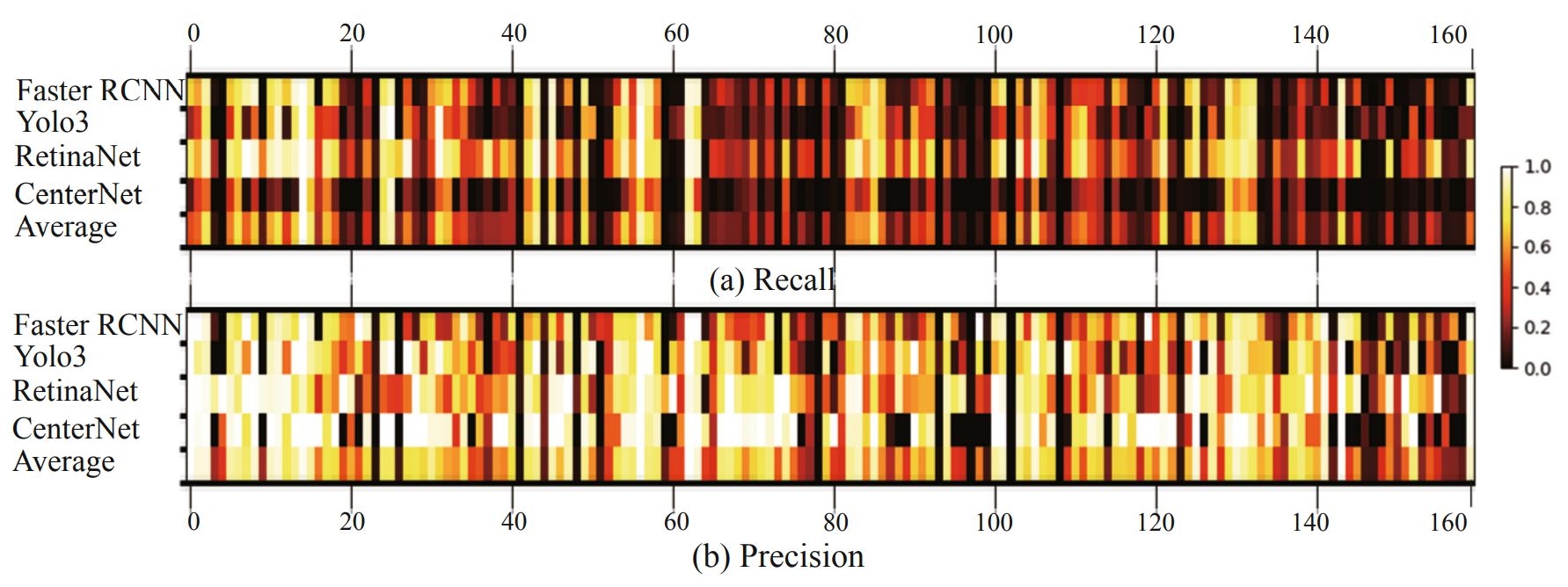
3. 基准模型测试结果
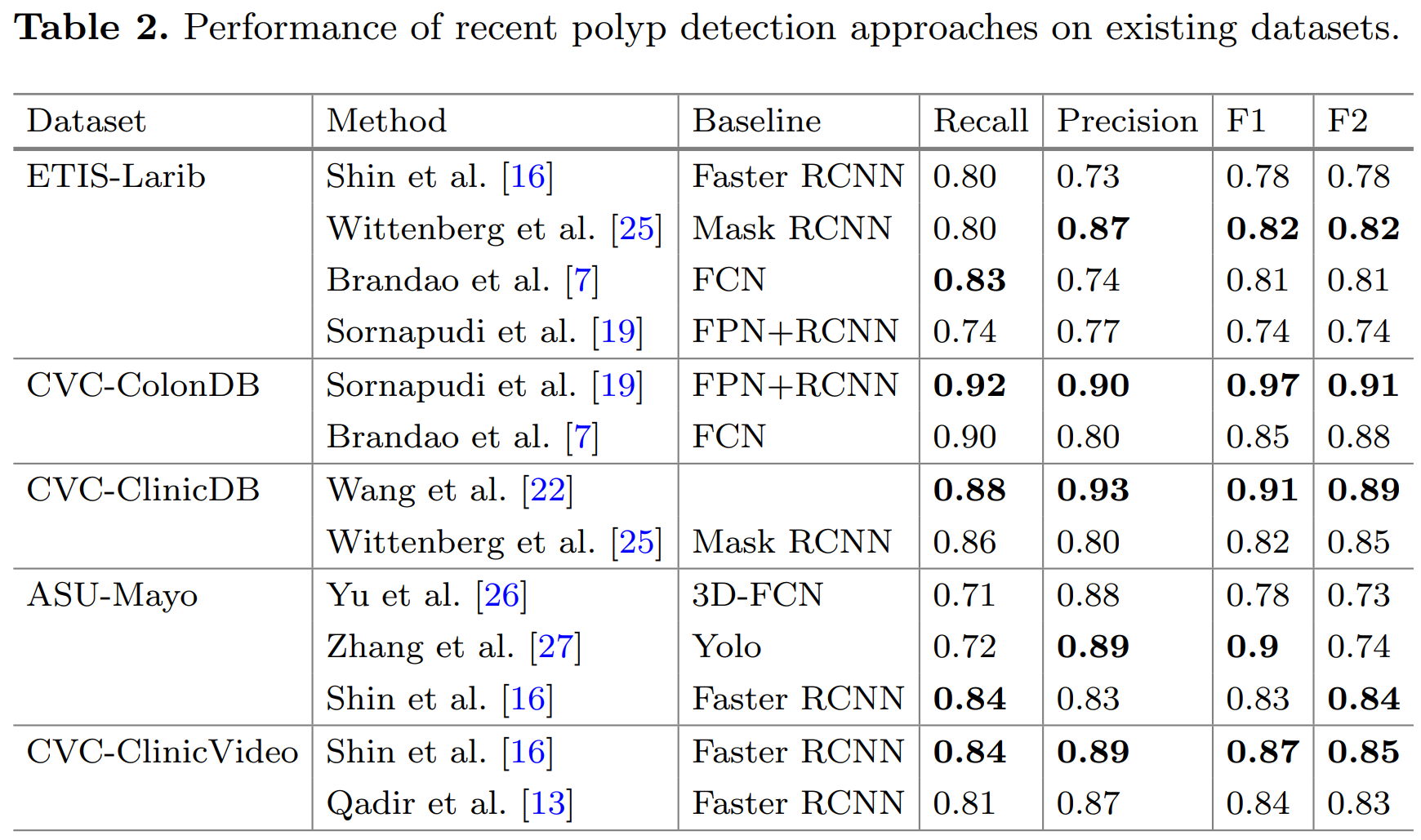
测试方法:
- We choose ResNet-50 as the backbone for Faster R-CNN, RetinaNet, and CenterNet, while Yolo3 adopts DarkNet as its backbone.
- All the models are pre-trained on ImageNet
- We train all detection networks on CVC-ClinicDB
- To prevent overfitting, data augmentation including image rotation, flipping, scaling, shearing, and motion blur is performed.
- We do not implement any post-training on specific videos for a fair comparison
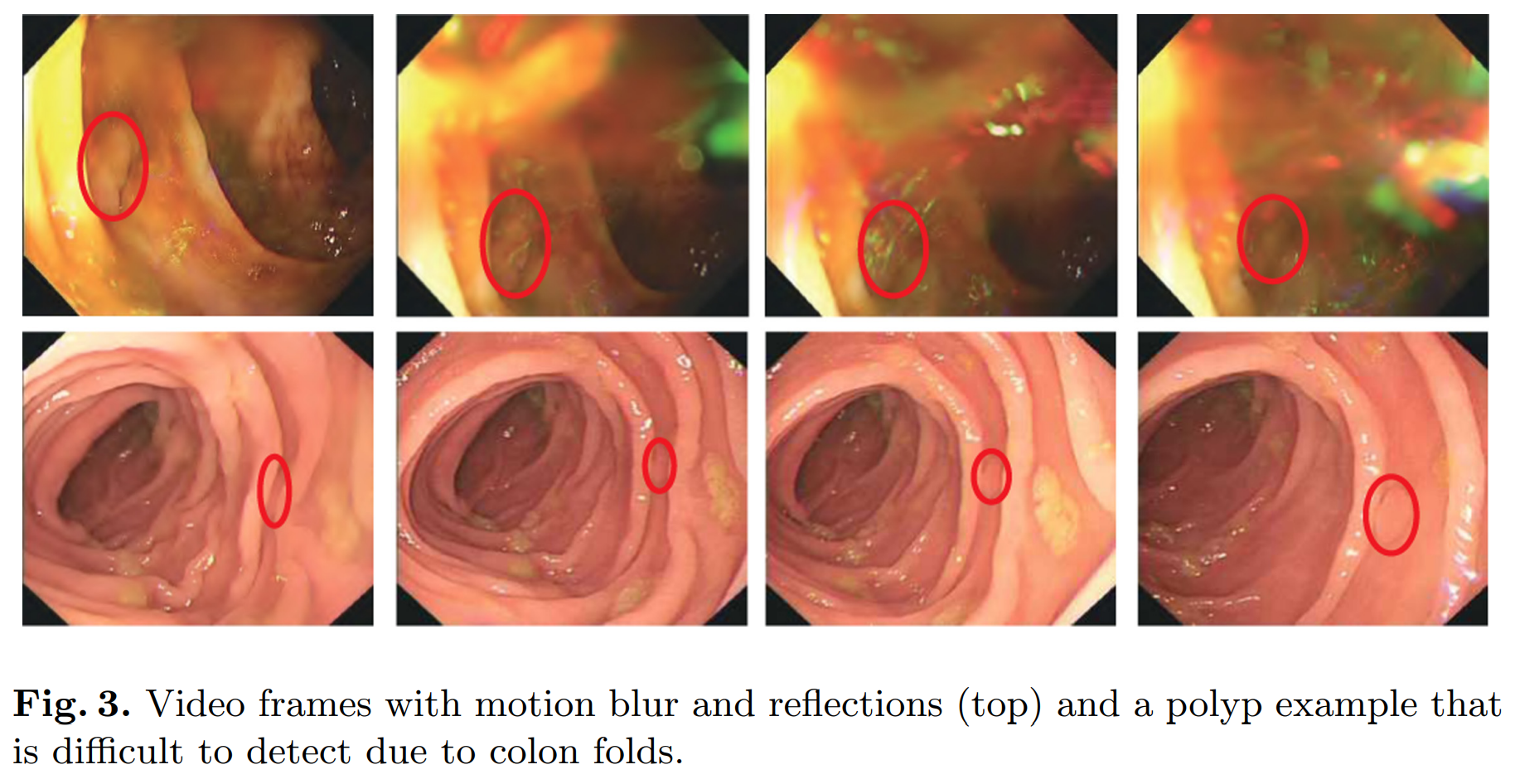
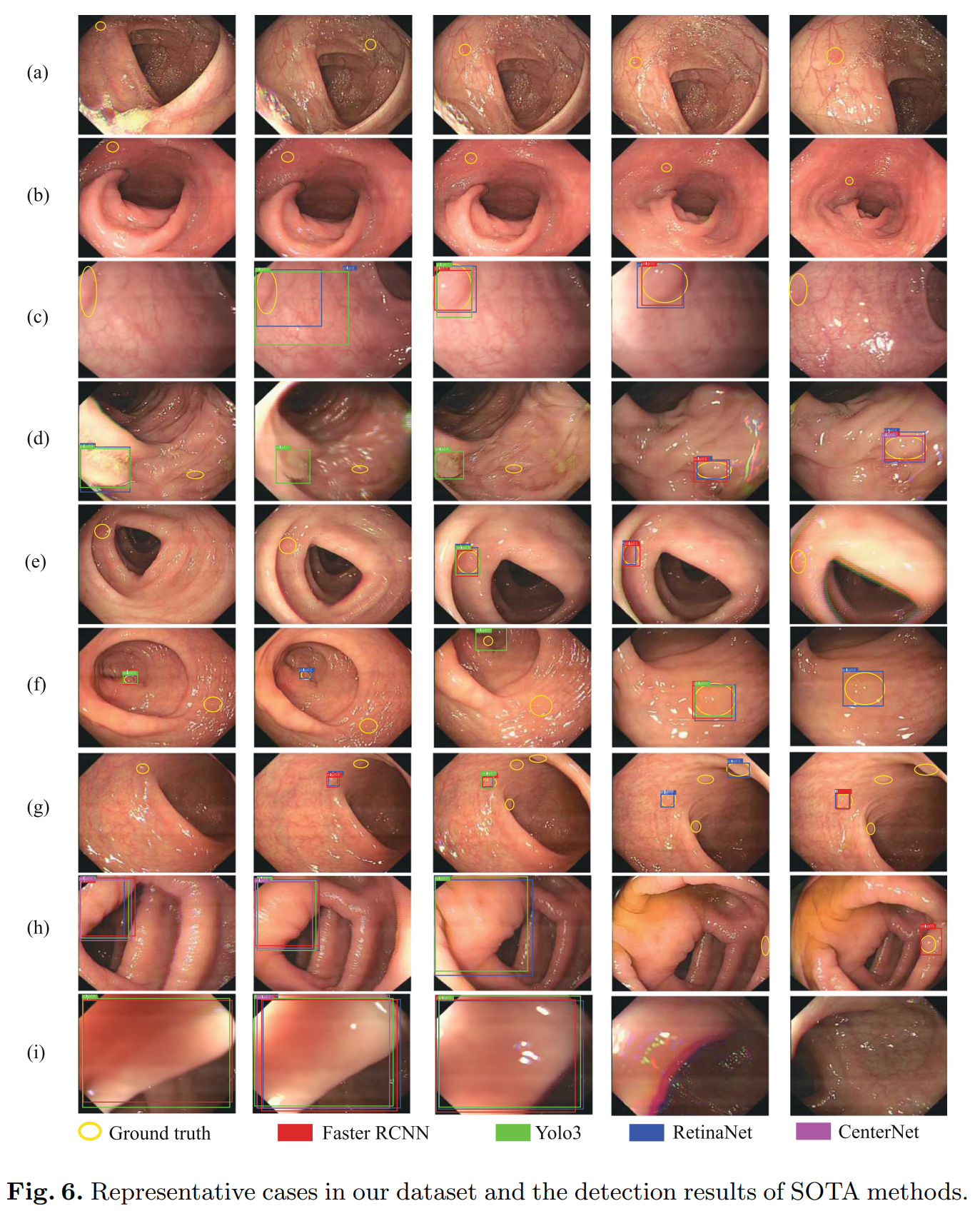
3. 错误分析
(a)(b):The small polyps
(c) to (f): specular reflections, small size, motion blur, colon folds, etc.
In case (d), a colorectal ileocecal valve is detected by Yolo3 by mistake
(e) and (g): multiple polyps
启发和思考
数据集注释内容
1
2
3
4
5
# Annotation example:
Annotations/1/0001.txt # Annotations/第几个视频/第几帧
2 # 息肉数量
19 306 50 355 # 第一颗息肉的bbox
66 118 89 181 # 第二颗息肉的bbox